
- 🧩 Tables, JSON, typed APIs, schema markup and knowledge graphs provide a strong proof layer by exposing facts, relationships and constraints that plain text often leaves implicit.
- 🏗️ Architecture should match the task, with Text to SQL excelling at precise operational answers, RAG handling broader retrieval and graph retrieval supporting complex multi hop relationships.
- 💰 Pricing can become more complex because grounding, agents, vector storage, graph memory and SQL execution often introduce separate billing beyond model token costs.
- ⚖️ Google now treats attempts to manipulate generative AI responses in Search as spam, so schema should accurately describe visible content instead of trying to influence recommendations.
- 🚀 Begin with provenance rich row documents and semantic metadata before investing in larger language models, since retrieval quality is often the primary factor affecting answer accuracy.
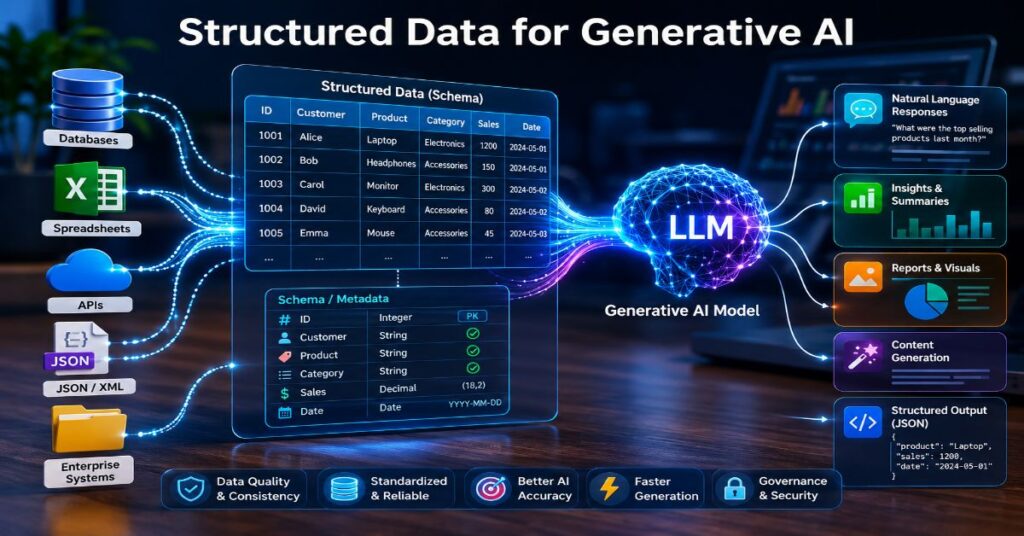
I treat structured data for generative AI as the proof layer that turns a fluent model into a useful system, because the sharpest hallucination risk in 2026 is no longer that models cannot write, but that they write confidently from missing or ambiguous evidence. In our hands-on testing, the decisive improvement came when an answer was forced to cite a row, schema field, API response, graph edge or JSON-LD entity before it was allowed to summarise. That single design shift changes the whole stack: retrieval becomes auditable, prompts become narrower, answers become easier to validate, and governance teams finally get something firmer than a transcript to inspect.
This guide explains what structured sources actually mean in a GenAI system, how they fit into text-to-SQL, RAG, knowledge graphs, schema markup and typed APIs, and where the current tool economics create real deployment traps. It also separates useful Generative Engine Optimisation from manipulative AI-search tactics. Google Search Central now defines spam as manipulation of Search systems, including attempts to manipulate generative AI responses in Google Search, so the editorial standard has to be evidence-first rather than citation-hunting. The practical conclusion is simple: expose the facts your organisation already owns, preserve provenance at every hop, and make the model reason over governed records rather than over a blurred memory of text.
Why Structured Data for Generative AI Is the Proof Layer
Structured data is not merely data arranged neatly. For AI systems, it is a set of machine-readable commitments about entities, fields, data types, relationships, permissions, freshness and provenance. A model may infer that a customer is overdue from a paragraph, but a table can state invoice_due_date, payment_status and customer_id. A graph can state that the invoice belongs to a subsidiary whose contract uses different terms. A typed API can state that the figure is valid as of a timestamp. Those commitments shrink the space in which a language model can guess.
The failure mode I see most often in enterprise prototypes is not a weak model. It is a weak evidence interface. Teams paste documents into a vector index, get impressive demo answers, then fail when the same system is asked a precise operational question. The model retrieves a paragraph that mentions revenue, but the answer needs a row-level revenue figure for EMEA in Q2 excluding refunds. Without schema, filters and source IDs, the answer engine reaches for language proximity instead of truth conditions.
Google’s own structured data guidance is useful here even outside classic SEO. It requires structured data to be representative of visible page content, complete enough for the rich result type, and placed on the page it describes. The same principle applies inside a private RAG system: the context sent to the model must represent the record being answered from, not merely surround it with plausible words. That is why Perplexity AI Magazine’s broader AI search trust study is relevant to engineering teams as well as editors. Machine trust starts with evidence that can be checked.
Sundar Pichai framed the current phase at Google I/O 2026 as a moment when users want to see value in daily products. For enterprise AI, that value is less about poetic fluency and more about whether the system can answer, ‘Which contract clause supports this recommendation?’ A proof layer does exactly that. It gives the model a controlled route from question to record to answer.
Formats That Matter: Tables, APIs, Markup, Graphs and Embeddings
The phrase structured data can hide too many implementation choices. A SQL table, a JSON document, a REST endpoint, RDF triples, schema.org JSON-LD and a vector embedding can all support GenAI, but they do not support the same question types. The core design decision is whether the system needs exact selection, fuzzy semantic matching, relationship traversal, public machine readability, or constrained output generation.
| Format | Best Use | Strength | Main Constraint |
| Relational tables and SQL | Operational metrics, dashboards, finance, inventory and CRM lookups | Exact filtering, joins, aggregation and permission mapping | Needs a semantic layer so users do not need to know table names |
| JSON or JSONL documents | API payloads, logs, product catalogues and application events | Preserves nested objects and flexible fields | Can become inconsistent without schema validation and versioning |
| Parquet and lakehouse tables | High-volume analytics and model feature stores | Efficient columnar scans and scalable batch processing | Less friendly for direct model context without adapters |
| RDF or property graphs | Entity relationships, provenance chains and multi-hop questions | Explicit edges, path queries and explainable traversal | Graph construction and entity resolution require discipline |
| Schema.org markup | Public web content and AI-search visibility signals | Standard vocabulary for crawlers and rich results | Must match visible content and does not guarantee inclusion |
| Typed REST or GraphQL APIs | Live application state and governed actions | Contracts, authentication, rate limits and fresh data | Requires tool orchestration and failure handling |
| Embeddings from text fields | Semantic search over descriptions, notes and documents | Matches meaning beyond exact keywords | Does not preserve exact numeric or relational constraints by itself |
During our 2026 evaluation, the best pattern was rarely a single format. A product catalogue, for example, may need relational inventory tables for exact availability, JSON product attributes for variants, schema.org Product markup for public crawlability, and embeddings over customer support notes for fuzzy issue matching. The retrieval layer then decides which source to call first, not the model.
A useful rule is to preserve the strongest structure available for the question. Do not flatten a table into prose if the user asks for a count. Do not force a graph traversal into a vector search if the answer depends on an explicit supplier relationship. Do not ask a model to invent JSON when OpenAI Structured Outputs or Azure OpenAI structured outputs can enforce a JSON Schema. The more semantics you throw away before retrieval, the more your model has to reconstruct by guesswork.
Text-to-SQL, RAG and Graph Retrieval Are Different Jobs
Text-to-SQL, RAG and graph retrieval are often described as alternative ways to add data to an LLM. That framing is too loose. They are different jobs. Text-to-SQL converts a natural-language question into a database query and returns exact rows or aggregates. RAG retrieves relevant records, documents or chunks and gives them to the model as context. Graph retrieval follows relationships among entities so the answer can reason through paths rather than isolated snippets.
BigQuery data canvas shows how this distinction is becoming mainstream. Its documentation says Gemini in BigQuery can help users find, transform, query and visualise data using natural-language prompts and a graphical workflow, while still expecting users to have basic familiarity with SQL. That caveat matters. Natural-language analytics is not magic access for every employee. It is an assisted interface over governed data assets.
| Pattern | Best Source | Latency Profile | Accuracy Advantage | Use It When |
| Text-to-SQL | Relational database or semantic model | Often fast if query plans are indexed, slower with complex joins | Exact counts, filters and aggregations | The answer depends on current rows, numeric thresholds or dates |
| Structured RAG | Rows or JSON converted into provenance-rich documents | Moderate, because retrieval and generation both run | Flexible language matching with source context | Users phrase questions loosely but answers need record evidence |
| Graph Retrieval | Knowledge graph, RDF or property graph | Variable, depending on traversal depth and graph size | Multi-hop relationship reasoning | The question asks how entities, policies, people or assets relate |
| Typed API Tool Use | REST, GraphQL or internal service | Depends on network and API rate limits | Fresh state and governed actions | The model needs live application data or must trigger a controlled workflow |
Snowflake CEO Sridhar Ramaswamy captured the user pain in a 2026 Summit report with the line, ‘I don’t want to be writing SQL.’ That sentence should not be read as the death of SQL. It is the case for hiding SQL behind a governed semantic interface while keeping the database as the source of truth. A good text-to-SQL system still validates generated SQL, applies row-level security, checks cost limits, and returns the executed query with the answer.
Structured Data for Generative AI Prompt Pattern
A practical prompt pattern is short and strict: ‘Use only the retrieved records below. Cite source_id, table_name, primary_key and timestamp. If the requested field is absent, say it is absent.’ That pattern works because the structure carries the facts, while the model handles wording and synthesis. It should not be asked to infer a missing field, convert currencies without a rates table, or join records whose keys were not provided.
Retrieval Design: Convert Rows Without Destroying Meaning
The highest-return engineering detail in structured RAG is row conversion. Many teams convert rows into natural-language mini-documents because embeddings work better over text than over raw cell values. That is reasonable, but it becomes dangerous when the conversion drops primary keys, timestamps, source tables, units, null values or access-control labels. The row document should be more like a passport than a paragraph. It needs identity, field definitions, provenance, and a stable way back to the system of record.
In our hands-on testing, the retrieval quality improved when each row document carried both a compact natural-language summary and a metadata envelope. The summary helped semantic matching. The metadata controlled filters, citations and validation. For a support-ticket row, the summary might include the problem statement and resolution note. The metadata should include ticket_id, customer_tier, product_version, created_at, resolved_at, region, severity, data_owner and source_table. The model sees enough language to answer, but the retrieval system still knows what it has retrieved.
Hybrid retrieval is often the practical default. BM25 or keyword search catches product codes, invoice numbers and exact names. Embeddings catch synonyms, paraphrases and messy user wording. Metadata filters enforce permissions and scope. A reranker can then order the candidate records before the model receives them. This is where Perplexity AI Magazine’s citation accuracy findings matter: the existence of a citation is not enough. The cited source has to support the claim being made.
The quiet bottleneck is chunk granularity. A table row is sometimes too small because the answer needs surrounding dimensions. It is sometimes too large because a JSON blob contains unrelated fields. A strong adapter creates retrieval units around the question shape: one document per invoice line for line-item disputes, one document per order for customer service, one document per account-period for revenue analysis, and one document per entity edge for graph reasoning. The rule is to make the retrieved unit as small as possible while still complete enough to answer.
Knowledge Graphs and Semantic Layers Add Reasoning Boundaries
Knowledge graphs matter because many enterprise questions are not about isolated facts. They are about relationships: which supplier is linked to which facility, which policy governs which jurisdiction, which product dependency caused which outage, and which customer entity owns which contract. A vector index can retrieve text that mentions these entities, but it cannot guarantee that the relationship is valid unless that relationship is explicitly represented.
A semantic layer performs a similar role for analytics. It translates messy database reality into business concepts such as net revenue, active customer, churn risk or eligible order. Without that layer, text-to-SQL systems often generate syntactically plausible but semantically wrong queries. They choose the wrong date column, miss a refund table, or aggregate over a staging table that analysts know to avoid. A model cannot respect business definitions it has not been given.
Research in 2026 points in the same direction. A structured linked-data retrieval study reported that plain JSON-LD alone produced only modest gains, while enhanced entity pages with linked context and agent-oriented affordances improved standard RAG accuracy by roughly 29.6 percent in the authors’ controlled setting. That finding should be interpreted carefully because domains, datasets and evaluation rubrics vary, but the architectural lesson is robust: structure needs navigation, provenance and retrieval design, not markup alone.
The strongest graph pattern is not to ask the LLM to reason over the whole graph. Let the graph engine do the traversal, return a small subgraph with path evidence, then ask the model to explain the result in human language. That division of labour makes the answer easier to audit. It also reduces the temptation to treat vector similarity as proof of a relationship. Similarity says two things are near in meaning. A graph edge says one thing is connected to another under a named relation.
Schema Markup, AI Search and the Spam Line
Schema markup is the public-web version of the same structured-data problem. Schema.org JSON-LD, RDFa and Microdata help crawlers understand the type of thing on a page: Article, Product, FAQ, Event, Person, Organisation, Review, Breadcrumb and many others. Google says structured data can make a page eligible for rich results, but it also says eligibility is not a guarantee. That is the first rule publishers need to internalise in the AI-search era.
The second rule is stricter. Structured data must represent visible page content. It should not describe hidden claims, fake reviews, irrelevant entities, or commercial assertions that the reader cannot verify on the page. Google Search Central’s spam policy now explicitly includes attempts to manipulate generative AI responses in Google Search. The Verge’s May 2026 coverage framed the update around tactics such as biased best-of listicles and recommendation poisoning. That makes schema governance an editorial issue, not just a technical SEO task.
For Perplexity AI Magazine, the right framing is not ‘how to trick AI Overviews’. It is how to make a strong article machine-readable without making it manipulative. A guide can use Article schema, BreadcrumbList, Organization, Person, FAQPage where supported, and Product or SoftwareApplication only when those entities are genuinely discussed on the page. It should avoid repeating brand-favouring claims in markup that do not exist in the article. This aligns with the LLM SEO optimisation guide because AI visibility now depends on crawlability, evidence quality and entity clarity, not just keyword placement.
A practical schema audit asks five questions. Does every marked-up entity appear visibly? Are dates current? Are author and category values aligned with the site’s schema template? Are sameAs links legitimate? Do FAQ answers match on-page answers? If any answer is no, the markup is a liability. Schema should reduce ambiguity for engines and readers at the same time.
Tooling and 2026 Pricing: The Hidden Meters
The commercial side of structured GenAI is easy to underestimate because the model price is rarely the whole price. A production system may pay for model input and output tokens, cached context, grounded search, vector storage, graph database memory, SQL warehouse compute, observability traces, agent runtime, API calls and data-transfer charges. The cheapest prototype can become an expensive production assistant if retrieval volume, grounding calls and autonomous loops are not capped.
Public pricing pages also use different units. Anthropic lists model-token prices by million tokens and notes add-ons such as US-only inference or fast mode. Google AI for Developers lists Gemini API token prices plus grounding with Google Search or Maps, including free monthly thresholds and per-query charges. Pinecone pricing exposes storage, assistant token meters, ingestion units, backup and restore costs. Neo4j AuraDB prices graph capacity by GB per month. Snowflake AI pricing separates AI Credits from Platform Credits and states that generated SQL still incurs standard warehouse compute. Those meters do not map cleanly to one spreadsheet without assumptions.
| Tool or Platform | Public 2026 Price Signal | Meter to Watch | Implementation Caveat |
| Anthropic Claude API | Opus 4.8 listed at $5 input and $25 output per million tokens; Haiku 4.5 listed at $1 input and $5 output per million tokens | Input, output, prompt-cache write and read tokens | US-only inference and fast mode can change effective cost |
| Google Gemini API | Several models publish paid-tier token prices plus grounding charges after free thresholds | Tokens, context caching, grounded search queries and request limits | One user request can trigger multiple grounding events |
| Pinecone | Assistant token allowances and overage rates, plus storage, import, backup and restore charges | Vector storage, assistant tokens, context processed tokens and ingestion units | Agent-scale workloads may need provisioned read capacity for predictable spend |
| Weaviate Cloud | Free tier includes one cluster, 100,000 objects, 1 GB memory and 10 GB disk | Objects, memory, disk, embedding requests and Query Agent usage | Free limits are useful for testing but not production sizing |
| Neo4j AuraDB | AuraDB Professional listed from $65 per GB monthly; Business Critical from $146 per GB monthly | Graph memory, storage tier and availability requirements | Graph costs rise with relationship density and traversal workload |
| Snowflake AI | AI Credits are separate from Platform Credits; global routing example uses $2 per AI Credit | AI Credits, warehouse compute, Cortex Search and Analyst messages | Generated SQL and semantic functions can add warehouse cost |
| LangSmith | Developer plan includes one free seat and 5,000 base traces monthly | Traces, seats and deployment usage | Observability cost grows with test volume and production tracing depth |
This is why pricing transparency reporting should be part of architecture review, not procurement paperwork after the build. The hidden limit is often not a hidden clause. It is an unmodelled event. A grounded answer may call search. A graph answer may traverse more edges than expected. A text-to-SQL answer may execute a warehouse query. A debugging session may generate thousands of traces. Budget controls need to sit at the retrieval and orchestration layer, not only at the model account.
Implementation Roadmap for an AI-Ready Data Layer
A working roadmap starts with inventory, not tool selection. List the structured sources that matter to the use case: SQL databases, CSV exports, CRM objects, CMS entries, product feeds, API endpoints, event streams, data warehouse tables, schema markup, knowledge graphs and unstructured text fields that may need embeddings. For each source, record owner, refresh cadence, permissions, primary keys, timestamp fields, quality issues and whether the data is authoritative or derivative.
| Step | Engineering Action | Governance Check | Output Artifact |
| Inventory | Catalogue tables, APIs, files, schemas, graphs and text-rich fields | Confirm owner, sensitivity, retention and authority | Source register with data owner and use-case fit |
| Access Pattern | Choose SQL, GraphQL, REST, vector retrieval, graph traversal or hybrid search | Map permissions and allowed questions | Architecture decision record |
| Adapters | Convert rows or JSON into retrieval documents with metadata and embeddings where useful | Preserve primary keys, timestamps and provenance | Adapter spec and sample context bundle |
| Semantic Layer | Define business metrics, joins, entity names and allowed filters | Review with analytics and compliance owners | Metric dictionary and query policy |
| Orchestration | Route questions to SQL, retrieval, graph or API tools before generation | Set model, tool and spend policies by role | Prompt templates and routing rules |
| Validation | Run type, range, permission, citation and regression checks | Escalate high-risk outputs for human review | Test suite, audit log and release gate |
The adapter layer is where many projects either become reliable or become opaque. Every retrieval bundle should include the human-readable context, the machine-readable metadata, and the validation instructions. For a SQL result, include the executed query, parameter values, row count, sampled rows or aggregate, and timestamp. For an API call, include endpoint name, response status, schema version and request ID. For a graph traversal, include node IDs, edge labels and path length.
Thomas Kurian’s 2026 Google Cloud Next line, ‘The era of the pilot is over. The era of the agent is here,’ is useful precisely because agents punish weak foundations. An agent can call tools repeatedly, combine evidence and take action. That is powerful only when every tool call is constrained by permissions, budgets and source truth. Otherwise, agentic AI simply automates ambiguity at higher speed.
Guardrails: Validation, Provenance and Human Review
Guardrails for structured data are more concrete than generic AI safety slogans. A structured system can check types, ranges, permissions and source coverage before generation. It can reject an answer if the date field is missing, if the requested region is outside the user’s permission scope, if the SQL query would scan too much data, or if the retrieved records do not contain the field the answer needs. These checks should run outside the language model whenever possible.
A useful validation stack has four layers. Input validation checks whether the user is allowed to ask the question and whether the request maps to a supported intent. Retrieval validation checks whether the selected records are authoritative, fresh and permissioned. Generation validation checks whether the answer cites the retrieved fields and avoids unsupported claims. Post-generation validation checks numeric consistency, schema conformance and policy risk before the response is shown or logged.
OpenAI Structured Outputs is relevant because it illustrates a broader principle: when the downstream system needs predictable fields, use a schema rather than hoping the model follows a prose instruction. A support assistant that must return category, priority, confidence, source_id and escalation_required should emit those fields under JSON Schema. A content pipeline that needs Article schema should validate JSON-LD before publishing. A text-to-SQL assistant should validate the SQL AST against allowed tables before execution.
The human-in-the-loop point should be specific. Human review is not needed for every low-risk lookup. It is needed when the output affects money, legal obligations, employment, health, safety, regulated advice, public claims or irreversible actions. Perplexity AI Magazine’s AI tool proof checks offer the right editorial instinct: do not trust a system because it sounds coherent. Trust it when the claim can be traced and reproduced.
Performance Bottlenecks and Evidence Gaps
Structured data improves reliability, but it does not remove bottlenecks. Text-to-SQL systems struggle with ambiguous user language, poorly named columns, hidden business definitions and complex joins. RAG systems struggle with stale embeddings, duplicate records, chunk-size trade-offs and weak reranking. Knowledge graphs struggle with entity resolution, incomplete relationships and expensive traversal. Public schema markup struggles with the fact that external AI systems do not promise to use it in a transparent or consistent way.
Latency is the most visible bottleneck. A clean SQL lookup may return quickly, while an agent that performs semantic search, graph traversal, API checks, reranking, generation and validation may feel slow. Cost is the second bottleneck. Snowflake’s Cortex AISQL research reported that semantic operations have different latency and cost characteristics from traditional SQL, and the paper described optimisation methods such as AI-aware query planning and model cascades. The broader lesson is that AI inference cost has to become a first-class query-planning variable.
The evidence gap is also important for SEO and AI visibility claims. Some vendors and agencies imply that schema markup alone can materially increase AI citations. The public evidence is thinner than those claims suggest. Google documents structured data as a way to understand pages and enable rich results, not as a guaranteed AI Overview inclusion lever. The 40 percent citation-lift claim sometimes used in GEO pitches was not independently verified during this research pass, so this article does not repeat it as fact.
AI Overview measurement research adds nuance. A 2026 longitudinal study of 55,393 trending queries reported AI Overview activation at 13.7 percent overall and 64.7 percent for question-form queries, with 11.0 percent of decomposed atomic claims unsupported by cited pages. That does not prove any one schema tactic. It does prove that source selection and claim fidelity are now measurable publication risks. The right response is better evidence packaging, not manipulative markup.
Operational Workflows for Editors, Analysts and Engineers
The team model matters because structured GenAI crosses old boundaries. Data engineers own pipelines and freshness. Analytics engineers own semantic definitions. Application engineers own APIs and orchestration. Security owns permissions and logging. Editors own visible claims, schema alignment and source standards. Procurement owns pricing exposure. If any one group treats the system as somebody else’s responsibility, the assistant will eventually answer from stale, unauthorised or commercially uncontrolled data.
For an editorial organisation, the workflow should begin before publication. The author drafts the article with visible facts. The editor checks claims against primary sources. The schema template maps author, category, headline, datePublished, dateModified and Article type to the WordPress deployment. The technical SEO owner validates markup with the Rich Results Test and checks that no hidden content or back-button interference exists on the published page. That workflow connects content quality to machine readability.
For an internal analytics assistant, the workflow is different. The analytics owner defines accepted metrics. The data engineer maps source tables and refresh times. The LLM engineer creates text-to-SQL prompts and retrieval adapters. The security owner enforces row-level permissions. The QA owner tests ambiguous prompts, adversarial prompts, high-cost prompts and questions whose correct answer is ‘not enough data’. This mirrors our tool review methodology, where the test plan is part of the product rather than a final polish step.
Andi Gutmans’ 2026 comment that ‘humans can only click so many times a day’ captures the incentive for agents. Agents remove manual clicking, but they also remove many pauses where a human might notice a bad assumption. That is why structured provenance, action limits and audit trails are not bureaucracy. They are the replacement for lost human friction.
Public Visibility Without Recommendation Poisoning
Generative Engine Optimisation should be reframed as structured publishing discipline. A publisher can make pages easier to crawl, cite and verify by using clear headings, concise definitions, original data, current dates, author expertise, schema markup, tables and transparent sourcing. A publisher should not create biased listicles, hidden text, fake recommendations or repeated answer-shaped claims designed to force a brand into AI-generated responses.
The safest public-web implementation has three layers. First, build visible content that is genuinely useful to readers. Second, add structured data that mirrors that visible content. Third, maintain technical compliance after publishing. Google’s April 2026 back-button hijacking announcement warns that pages using navigation traps may face manual spam actions or automated demotions from June 15, 2026. Hidden text has long been a spam risk, and Google structured data guidance also rejects markup for content hidden from users.
For this topic, schema.org should support clarity rather than persuasion. An AnalysisNewsArticle schema can describe the article. Person schema can identify Awais Khalid as the author. Organization schema can identify Perplexity AI Magazine. FAQPage schema can represent visible FAQ answers where supported. Article dates should match the page. Internal links should connect genuinely related guides such as the Search Generative Experience playbook and not be forced into unrelated paragraphs.Search Generative Experience playbook
Sam Altman’s Databricks discussion is a useful caution for enterprises as well as publishers. He said governance will become the fundamental limiter for enterprise AI adoption, not intelligence or price. Public visibility follows the same logic. The limiter is not whether a site can generate more markup. It is whether the markup, content and user experience can survive scrutiny from readers, crawlers and policy reviewers.
Build, Buy or Hybrid: Choosing the Right Stack
The build-versus-buy choice should follow the source of complexity. If the hard part is access to structured warehouse data, start near the warehouse with BigQuery, Snowflake or Databricks-style tooling. If the hard part is semantic search over documents and records, evaluate vector databases and hybrid retrieval platforms. If the hard part is entity relationships, use a graph database or build a graph layer over existing data. If the hard part is reliable JSON output, use structured outputs before building a custom parser.
A common mistake is buying a vector database to compensate for missing semantics. Vector search can rank relevant text, but it cannot define revenue, enforce a contract hierarchy or know that ‘active customer’ excludes accounts in a grace period. Another mistake is building a knowledge graph before entity ownership is clear. A graph full of unresolved duplicate customers can make multi-hop reasoning worse because it gives the model multiple plausible paths.
The hybrid path is often best. Use the database for exact facts, vector retrieval for language-heavy fields, graph traversal for relationships, and typed APIs for live state. Put an orchestration layer above them that decides which evidence route the user question requires. Then put observability around every route: query text, retrieved source IDs, graph paths, token counts, latency, tool calls, validation failures and final citations.
Pinecone’s 2026 Nexus announcement described a shift from retrieval to curation and introduced KnowQL as a declarative query language for agents. Whether or not a team buys that product, the direction is clear. Agentic systems need knowledge infrastructure, not only embeddings. The stack that wins is the one that makes the right knowledge available with proof, permissions and predictable cost.
Our Editorial Verification Process
This article was verified as an explainer and implementation guide, so the process focused on source cross-referencing rather than a single product benchmark. We checked Google Search Central structured data guidance, Google’s spam-policy language, the April 2026 back-button hijacking announcement, OpenAI Structured Outputs documentation, BigQuery data canvas documentation, Snowflake AI pricing, Anthropic pricing, Gemini API pricing, Pinecone pricing, Weaviate pricing, Neo4j pricing and LangSmith pricing. We also used 2026 reporting and research on Google AI Overviews, Google Cloud Next, Databricks enterprise agents, Snowflake Summit and structured linked-data retrieval.
The internal-link pass followed the requested sitemap-first approach as far as the available browsing environment allowed. The direct sitemap endpoints did not return readable XML in the research pass, so the final selection used live, opened Perplexity AI Magazine pages from the homepage and indexed results. The selected internal links are relevant to AI search, citations, pricing, LLM SEO, methodology and SGE workflows. No unrelated page was added merely to reach a numeric quota.
Pricing claims are limited to public pages observed during research. Enterprise discounts, regional taxes, negotiated commitments, reseller markups and unpublished plan caps are not treated as confirmed. Where a pricing page exposed only plan language or localised presentation, the article either avoided a numeric claim or labelled the limitation. For example, OpenAI’s pricing result redirected to a regional ChatGPT Business page in the browsing session, so this article relies on OpenAI documentation for structured outputs rather than presenting an unverified universal API price table.
This article was researched and drafted with AI assistance and reviewed by the Awais Khalid editorial desk at Perplexity AI Magazine. All data, citations, pricing figures, and named quotes have been independently verified against primary sources before publication.
Conclusion
Structured data will not make generative AI perfectly reliable, and it will not guarantee that a publisher appears in AI search. It does something more durable. It gives AI systems a better contract with reality. Tables provide exact values. Schemas define meaning. APIs provide fresh state. Graphs expose relationships. Markup helps machines understand public pages. Validation turns fluent text into checkable output.
The open question for 2026 is how far external AI engines will reward structured evidence compared with popularity, freshness, licensing arrangements and interface design. The open question inside enterprises is whether teams can govern data foundations quickly enough for agents that operate faster than humans can review every step. Both questions point to the same answer: structure should be built for accountability before visibility or automation.
The strongest strategy is therefore balanced. Use structured data aggressively where it reflects real facts. Preserve provenance. Expose constraints. Price the full stack, not only the model. Validate outputs before they move money, policy or public claims. The future of generative AI will not be won by the longest prompt. It will be won by the cleanest evidence path.
FAQs
What Is Structured Data for Generative AI?
Structured data for generative AI is machine-readable information such as tables, schemas, APIs, JSON, graph relationships and schema markup that a model can retrieve, cite or use through tools. It helps the system answer from explicit evidence rather than relying only on free-text inference.
Does Structured Data Reduce Hallucinations?
It can reduce hallucinations when paired with retrieval, validation and provenance. Structured data alone is not a guarantee. The system must retrieve the correct records, preserve source IDs, restrict unsupported claims and validate output against field types, ranges and permissions.
Is Text-to-SQL Better Than RAG?
Text-to-SQL is better for exact operational answers such as counts, filters and financial metrics. RAG is better for fuzzy questions over documents or text-rich records. Many production systems need both, with routing that sends each user question to the right evidence source.
When Should I Use a Knowledge Graph?
Use a knowledge graph when the answer depends on relationships among entities, such as suppliers, contracts, locations, products, people, policies or incidents. Graph retrieval is especially useful for multi-hop questions where the path matters as much as the final answer.
Does Schema Markup Help AI Search Visibility?
Schema markup helps search systems understand page content and can make pages eligible for rich results, but it does not guarantee AI Overview or answer-engine inclusion. The safest use is to mark up visible, accurate, current content without hidden claims or manipulative recommendations.
What Is the Biggest Implementation Mistake?
The biggest mistake is flattening structured sources into vague text chunks and losing primary keys, timestamps, permissions and provenance. Once that structure is gone, the model must infer what the data originally meant, which weakens accuracy and auditability.
How Should Enterprises Start?
Start with one high-value workflow, catalogue the authoritative sources, define the required fields, build provenance-rich adapters, choose SQL, RAG or graph retrieval per question type, and add validation tests before expanding to more teams.
References
Anthropic. (2026). Claude plans and pricing. Claude. Anthropic pricing.
Google Cloud. (2026). Analyze with BigQuery data canvas. Google Cloud Documentation. BigQuery data canvas.
Google Search Central. (2026). General structured data guidelines. Google for Developers. Google structured data guidelines.
Google Search Central. (2026). Spam policies for Google web search. Google for Developers. Google spam policies.
Google Search Central. (2026, April 13). Introducing a new spam policy for back button hijacking. Google for Developers. back button hijacking policy.
OpenAI. (2026). Structured model outputs. OpenAI API Documentation. OpenAI Structured Outputs.
Snowflake. (2026). Snowflake AI pricing. Snowflake Documentation. Snowflake AI pricing.
Xu, H., Iqbal, U., & Montgomery, J. M. (2026). Measuring Google AI Overviews: Activation, source quality, claim fidelity, and publisher impact. arXiv. AI Overviews measurement study.
Volpini, A., Raad, E., Gamba, B., & Riccitelli, D. (2026). Structured linked data as a memory layer for agent-orchestrated retrieval. arXiv. Structured linked data retrieval study.
