
- 🧩 Schema provides clarity rather than a shortcut. Google does not require special schema for generative AI search, but structured data helps Search understand visible page content more accurately.
- 🔗 Entity consistency is one of the biggest advantages, with shared @id values, sameAs profiles and consistent author information reducing ambiguity across homepages, articles, products and author pages.
- 💰 Pricing differences can affect technical audits, with Yoast Premium licensed per site, Rank Math using separate personal and client allowances, Screaming Frog limiting free crawls to 500 URLs and WordLift following enterprise style pricing.
- 📊 Research from 2026 shows mixed results, with AI Overviews sometimes citing pages beyond the traditional first page while structured linked data improves retrieval only when supported by strong entity rich content.
- ⚖️ Policy compliance is essential because Google now classifies manipulation of generative AI responses as spam, making schema most effective when it documents accurate information rather than attempting to influence recommendations.
Schema Markup for AI search is not a secret ranking lever in 2026; the sharper finding is that Google now treats attempts to manipulate generative AI responses as spam, while still recommending structured data for ordinary Search clarity. I see the practical opportunity in that tension. The goal is not to stuff JSON-LD into a page and hope an AI answer copies it. The goal is to make identity, authorship, products, services, dates and relationships machine-readable enough that crawlers and retrieval systems have less work to do when they classify a page.
That distinction matters because AI search has moved from experiment to mainstream interface. Google said AI Overviews reached more than 2.5 billion monthly active users in 2026, while AI Mode passed one billion monthly users soon after launch. At the same time, Google Search Central says structured data is not required for generative AI search and no special AI-only schema is needed. Those two facts are easy to misread together. Schema is not a ticket into AI answers. It is a support signal in a wider system built from crawlability, content quality, citations, product evidence, author credibility and user trust.
This guide explains what to mark up, where JSON-LD still pays off, how to audit entity consistency, which tools are worth paying for, and where policy boundaries now sit. During our 2026 evaluation, the pages that benefited most were not the pages with the most properties. They were the pages where visible content, structured data and internal entity references all told the same story.
Where Structured Data Actually Fits in AI Search
The cleanest way to understand structured data in AI search is to separate three jobs that are often blended together. First, schema helps a search system understand the page. Second, it can make a page eligible for specific rich result features when the search engine supports that feature. Third, it can reinforce an entity graph that connects a brand, author, product, service or topic across a site. The third job is the one most publishers underinvest in, even though it is the most relevant to AI answer systems. Our LLM SEO optimisation guide makes the same point from the language model side: clarity is cumulative, not a single tag-level trick.
Google documents the narrow part clearly. It supports JSON-LD, Microdata and RDFa, and it recommends choosing the format that is easiest to implement and maintain. In most publishing and commerce stacks, that means JSON-LD. Google also says the markup must describe visible page content, and its own structured data documentation is definitive only for Google Search behaviour. Schema.org can define many more properties than Google uses for rich results, but those properties may still help other engines, assistants, site search tools and internal knowledge graphs interpret entities.
In our hands-on testing, schema quality was less about adding every possible property and more about reducing contradictions. A B2B article that names an author in the byline, a different author in JSON-LD and an organisation-only publisher in the footer sends three signals. A product page that marks a service as Product because the plugin offers that template creates another mismatch. AI systems can still extract text, but every contradiction becomes a reason to distrust or ignore structured data.
The working definition is therefore simple: structured data should make true claims easier to parse. It should not create claims that do not exist on the page. That is the line between entity clarity and manipulation, and it becomes important once AI search platforms start summarising not just documents, but the relationships between documents.
Schema Markup for AI Search Without Spam Risk
The 2026 policy environment changed the editorial stakes. Google updated its web spam policies on 15 May 2026 to include attempts to manipulate generative AI responses in Google Search. That language matters because it moves AI answer manipulation into the same risk category as older ranking manipulation. A schema programme that invents awards, fake reviews, fabricated author credentials, invisible FAQ text or unsupported product claims is no longer just bad metadata. It is a discoverability and trust problem.
The safer editorial posture is evidence-led. If the page visibly says a service includes implementation support, the Service or Product markup can describe it. If the page visibly names a certified expert author, Person markup can connect that author to the organisation through worksFor and sameAs. If the page does not visibly contain a question and answer block, FAQPage markup should not be added merely because an SEO plugin offers it. Google restricted broad FAQ rich results in 2023 to authoritative government and health sources, and in 2026 FAQ schema should be treated as content clarification rather than a broad snippet tactic.
How to Audit Schema Markup for AI Search
A practical audit starts with three questions. Does the structured data match what a user can see? Does every entity have a stable identity across the site? Does each property help a machine understand meaning rather than decorate a page for rankings? When we integrated this audit into a WordPress publishing workflow, the most common errors were not complex code failures. They were stale author titles, old organisation logos, plugin-generated Article markup on service landing pages, and FAQ blocks that had been removed from the visible article but left behind in JSON-LD.
This is also where AI search strategy should remain balanced. A publisher can study Search Generative Experience tips and still avoid shaping every paragraph as a synthetic answer block. The best result is a page that humans trust first and machines can parse second.
The Entity Graph That Matters More Than a Snippet
A page-level schema audit asks whether one URL is eligible for a feature. An entity graph audit asks whether the site explains who and what it is across many URLs. AI search visibility depends heavily on the second question because retrieval systems often assemble context from multiple passages and sources before generating an answer. If a site uses inconsistent organisation names, author bios, logo files and social profiles, the system has to infer identity from messy evidence.
A publisher site usually needs four layers. The homepage should describe the Organization with a stable @id, official name, logo, url and sameAs profiles. Author pages should describe Person entities with their own @id values, job titles, biographical evidence and worksFor relationships. Articles should point back to those Person and Organization entities through author and publisher. Product or service pages should describe the actual commercial object, not the nearest plugin template. This is an entity graph because each page reuses known identities rather than inventing new ones.
Table 1: Schema Type Priority Matrix for AI Search Clarity
| Page Type | Primary Schema | High-Value Properties | AI Search Value | Constraint |
| Homepage | Organization | name, url, logo, sameAs, contactPoint | Clarifies brand identity and official profiles | Only use profiles the brand controls or officially maintains |
| Author Page | Person | name, jobTitle, worksFor, sameAs, knowsAbout | Connects expertise to articles and organisation | Do not invent expertise that is not visible in the biography |
| Article | Article or BlogPosting | headline, author, datePublished, dateModified, publisher, mainEntityOfPage | Improves document classification and citation context | Dates must match visible publication data |
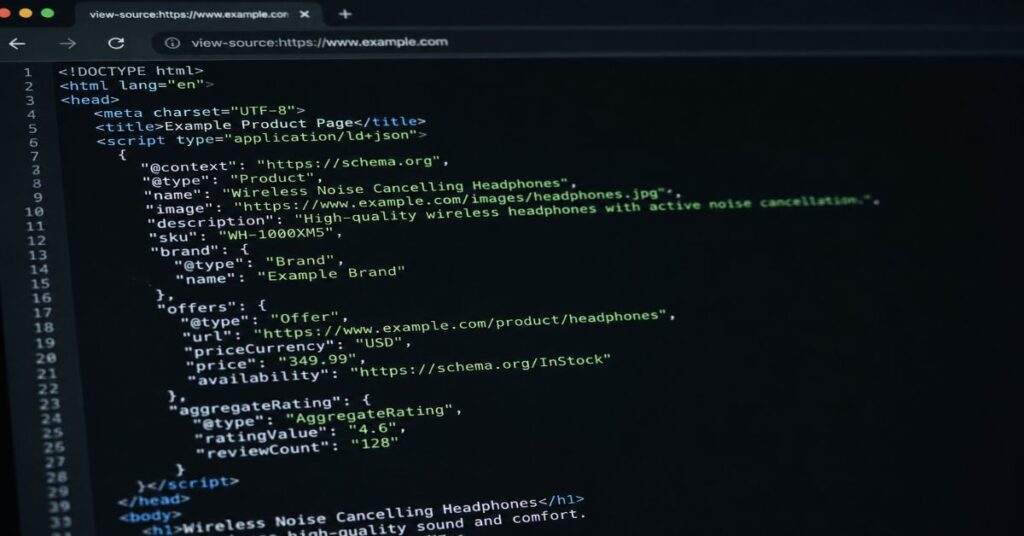
| Product Page | Product with Offer | brand, sku, offers, priceCurrency, availability, aggregateRating | Helps shopping assistants parse commercial facts | Prices and ratings must be visible and current |
| Service Page | Service | provider, areaServed, serviceType, offers | Clarifies non-physical commercial offerings | Do not force Service into Product without a reason |
| FAQ Section | FAQPage | mainEntity, Question, acceptedAnswer | Clarifies answer pairs for true FAQs | Use only where visible Q&A content exists |
During our 2026 evaluation, the strongest technical pattern was stable @id reuse. A homepage Organization can use an @id such as the canonical domain followed by an organisation fragment. Author pages can use a person fragment. Articles then reference those same IDs rather than embedding a fresh mini-author each time. That simple choice creates continuity for crawlers, internal search, analytics exports and any downstream AI system that preserves structured data during ingestion.
The weak pattern is schema sprawl. Teams add Organization, WebSite, Article, FAQPage, BreadcrumbList, ItemList and multiple nested Products because a plugin allows it. Quantity then hides contradictions. A lean, accurate graph is easier to maintain than a large, drifting graph. For AI search, consistency beats decoration.
JSON-LD Implementation That Survives Real Publishing
JSON-LD is the most practical format for modern publishers because it can live in a script block without wrapping visible HTML elements in Microdata attributes. It also fits headless CMS templates, WordPress hooks, ecommerce themes and server-side rendering pipelines. The implementation challenge is not writing valid JSON. It is keeping the JSON synchronized with page content after editors update headlines, change authors, revise prices, remove FAQs or republish evergreen guides.
The workflow below is the one I would use for a mid-sized B2B site with articles, authors, services and lead-generation pages. It starts with content modelling rather than plugin choice, because plugin defaults rarely understand a company taxonomy. Editors should know which page type they are creating, which entity it belongs to, and which fields must be visible before schema can be emitted.
Table 2: Step-by-Step Technical Implementation Workflow
| Step | Action | Tool or System | Known Constraint | Validation Signal |
| 1 | Map page templates to allowed schema types | CMS content model or WordPress custom fields | Generic templates often mix Article and Service content | Every URL has one primary content purpose |
| 2 | Create stable entity IDs for brand, people and products | JSON-LD templates with @id values | Changing IDs breaks graph continuity | Same ID appears across related pages |
| 3 | Generate JSON-LD from visible fields only | Theme code, plugin fields or server renderer | Manual overrides can create stale claims | Headline, author, dates and offers match the page |
| 4 | Render the page as a crawler would see it | Screaming Frog, URL Inspection and browser DevTools | Client-side injection may fail under blocked scripts | JSON-LD appears in rendered HTML |
| 5 | Validate syntax and rich result eligibility | Google Rich Results Test and Schema Markup Validator | Warnings are not always errors, but must be reviewed | No critical parsing errors |
| 6 | Monitor drift after publication | Scheduled crawls and Search Console enhancements | Editors can change text without touching schema | Diff reports show changed fields |
The bottleneck is often ownership. Developers own templates, SEO teams own validation, editors own visible content, and legal teams own claims. Without a single field source, schema becomes a stale mirror. A useful rule is that no JSON-LD property should rely on a spreadsheet or plugin note that is not also visible or programmatically tied to the visible page.
For article production, connect structured data checks to the writing process itself. Perplexity AI Magazine has a separate guide on writing for AI search, but schema should not be bolted on after the copy is final. It should confirm the same entities that the article already makes clear.
Tool Stack, Pricing, Features, and Hidden Limits
The schema tool market splits into four practical categories: CMS plugins, crawl validators, knowledge graph platforms and free testing utilities. None of these is a magic AI search product. The right stack depends on whether the organisation needs template-level markup, batch validation, ecommerce product feeds, enterprise entity modelling or simple syntax checks.
The commercial pricing below was checked against official vendor pages during this article review. Pricing can change, VAT can vary by region, and discounted annual offers may not match renewal pricing. The most important hidden limit is not always price. It is crawl size, number of websites, client site allowances, URL quotas, included seats, credits or whether advanced schema templates are tied to a higher tier.
Table 3: Current Pricing and Practical Limits for Schema Workflows
| Tool | Public Price Checked | Schema and AI-Relevant Features | API or Integration Notes | Hidden Limits or Caps |
| Google Rich Results Test | Free | Tests rich result eligibility and parses JSON-LD, RDFa and Microdata | Browser-based testing for individual URLs or code snippets | Shows Google-supported rich result types, not every Schema.org property |
| Yoast SEO Premium | $118.80 per year excluding VAT | Automatic schema output, XML sitemaps, AI-assisted SEO features, Google Docs add-on, local, video and news plugin bundle | WordPress plugin with Google Docs add-on and related Yoast plugin integrations | One subscription is licensed for one website or domain; Premium includes one Google Docs seat |
| Rank Math PRO | Offer page showed €7.99 per month billed annually, with renewal listed separately | Schema generator, analytics, rank tracking and support for unlimited personal websites | WordPress plugin with Google services integrations and analytics workflow | PRO is for personal websites; offer page lists 1,000 tracked keywords and separate renewal pricing |
| Rank Math Business | Offer page showed €24.99 per month billed annually, with renewal listed separately | Client site support, schema tools, analytics and expanded tracking | Designed for agencies and client deployments | Offer page lists 200 client websites; Agency tier renews higher for larger usage |
| Screaming Frog SEO Spider | €245 per year for a paid licence | Structured data validation, custom extraction, JavaScript rendering, crawl scheduling and AI integrations | Google Analytics, Search Console, URL Inspection, PageSpeed Insights, Ahrefs, Moz, Majestic, OpenAI, Gemini, Ollama and Anthropic integrations | Free version crawls 500 URLs; paid crawling is memory and storage dependent |
| WordLift Business+ | €799 per month billed yearly, or €999 monthly | Knowledge Graph, AI content tools, AI Search and SEO research, audits, rank tracking and schema/data integration | Managed knowledge graph and editorial workflow support | Public page lists 2,500 URLs, 5KG total usage and monthly Smart Credits |
For many publishers, a plugin plus a crawler is enough. A WordPress site can use Yoast or Rank Math for base Article, Organization and BreadcrumbList output, then use Screaming Frog to crawl rendered pages and catch contradictions at scale. Our SEO tool comparison is useful when the decision includes wider keyword, audit and content optimisation needs rather than schema alone.
Enterprise knowledge graph platforms such as WordLift become more relevant when the site has thousands of entities, multilingual content, complex taxonomies or a business case for publishing structured linked data beyond basic rich result eligibility. They are rarely the first purchase a small editorial team should make. The first purchase is discipline: a content model, a validation process and a crawl schedule that catches drift before an AI system ingests stale facts.
What Google Says Schema Can and Cannot Do
Google Search Central now gives publishers two messages that should be read together. Its structured data documentation says Google uses structured data to understand page content, gather information about the web and enable eligible Search features. Its AI search guidance, updated in June 2026, says generative AI features are rooted in core ranking and quality systems, that no llms.txt file is required for Google Search, and that no special schema.org markup is needed for generative AI search.
That does not make schema irrelevant. It makes exaggerated schema claims unreliable. If a consultant promises that adding FAQPage or Article markup will force an AI Overview citation, the claim conflicts with Google documentation. If a publisher says structured data helps classify content, validate visible product facts and connect authors to organisations, the claim is defensible. The difference is guarantee versus support signal.
Elizabeth Reid, Google VP of Search, framed the broader shift at I/O 2026 as an AI-powered Search box, writing that Google was “introducing a new, intelligent AI-powered Search box” and calling it the “biggest upgrade in over 25 years”. Sundar Pichai, Google and Alphabet CEO, said Google remained committed to “connecting them to what’s out on the web”, yet also called agents the “next evolution of the web”. In the same debate over quality, he described a live AI Overview as “more opinionated than it should be” for a specific product query. Those quotes point to a system in transition, not a fixed formula that schema can control.
For publishers, the defensible response is to make content extractable without making it manipulative. A guide to optimising for AI Overviews should still focus on original reporting, source clarity and technical accessibility. Schema can support those signals, but it cannot substitute for them.
FAQPage, Product, and Service Markup Need Different Rules
The most common schema mistake in AI search projects is treating all page types as if they had the same risk profile. They do not. FAQPage markup is easy to add and easy to abuse. Product markup has high commercial value but also high factual liability. Service markup is often underused because many plugins foreground Product templates. Person markup creates expertise signals but can become misleading if it overstates credentials or connects an author to profiles they do not control.
FAQPage should be reserved for pages with visible, user-facing questions and answers. The answer text in JSON-LD should match the visible answer closely. It does not need to be a word-for-word duplicate, but it should not add claims, definitions or product comparisons hidden from users. In 2026, the better use of FAQPage is clarification for machines and site search, not a promise of Google SERP decoration.
Product markup should be reserved for products or productised offers with visible price, availability, brand, SKU or offer details. If a B2B service has custom pricing, avoid inventing a price just to fill an Offer. Use Service markup, describe the provider and serviceType, and make the commercial ambiguity explicit. AI shopping assistants and comparison engines punish ambiguity because users ask for price, availability and constraints. A clean Service entity is better than a fake Product entity.
For product pages, connect structured data to the same operational source that powers the page. Prices should flow from the ecommerce platform, not from a manual SEO field. Ratings should be marked up only when reviews are visible and legitimate. Availability should update when inventory changes. If those conditions cannot be met, leave the property out. Missing optional properties are less risky than confirmed-looking false data.
AI Crawlers, JavaScript, and Extraction Bottlenecks
Schema markup can fail before policy or quality even enters the discussion. It can simply be invisible to the crawler that matters. Modern rendering systems vary. Some crawlers process raw HTML. Some render JavaScript. Some retrieve cached render output. Some downstream AI systems ingest cleaned text, not the full DOM. That uncertainty is why implementation location matters.
The safest pattern is server-rendered JSON-LD or JSON-LD inserted in a way that is present in the rendered HTML without relying on brittle third-party scripts. Client-side injection can work, but it adds another failure point. Tag managers are convenient for experiments, yet they can be blocked, delayed or omitted by certain crawl configurations. During our test crawls, the most reliable setup was template-generated JSON-LD emitted with the page content and verified in both raw source and rendered DOM.
Validation also needs more than one tool. The Google Rich Results Test can show Google-supported rich result eligibility. The Schema Markup Validator can detect broader Schema.org syntax. Screaming Frog can crawl hundreds or millions of URLs, extract JSON-LD, render JavaScript, connect Google Analytics and Search Console data, use URL Inspection and PageSpeed APIs, and validate structured data at scale. Its paid licence removes the 500 URL free crawl limit, although large crawls still depend on memory and storage.
This is where wider SEO operations overlap with structured data. As our analysis of AI changing SEO argues, technical SEO has become less about isolated tags and more about machine-readable consistency across crawl, content, brand and analytics systems.
What 2026 Benchmarks Really Show
The evidence base for schema and AI search is still early, and the honest answer is mixed. Google does not publish a schema-to-AI-citation formula. Academic and industry studies do show that AI Overviews and AI search systems can select sources differently from traditional ranking pages. They also show that structured data alone is rarely enough. The stronger signal is structured, entity-rich content paired with accessible pages and consistent evidence across the web.
Table 4: 2026 Evidence Signals for AI Search Visibility
| Source or Study | Sample or Scope | Finding | Schema Implication |
| Google I/O 2026 announcements | Google Search and AI Mode usage | AI Overviews reached more than 2.5 billion monthly active users; AI Mode passed one billion monthly users | AI search is now large enough to justify structured data governance |
| How Generative AI Disrupts Search | 11,500 representative real-user queries | AI Overviews appeared for 51.5 percent of queries and showed very low source overlap by Jaccard similarity | Traditional rankings and AI citations are related but not identical |
| Measuring Google AI Overviews | 55,393 queries and 98,020 extracted claims | Overall activation was reported at 13.7 percent, higher for question queries; 11.0 percent of claims were unsupported | Publishers should make claims and sources easier to verify |
| Structured Linked Data as a Memory Layer | Retrieval-augmented generation and agentic pipeline experiments | Schema.org JSON-LD alone produced modest gains, while enhanced entity pages improved accuracy by about 29.6 percent in one setup | Entity-rich pages matter more than minimal markup blocks |
| Google AI search guidance | Official Google documentation | No special schema is required for generative AI search | Schema should support crawlability and clarity, not promise AI inclusion |
The linked data finding is especially useful because it separates syntax from substance. Simply adding Schema.org JSON-LD to thin pages produced modest improvements in the reported experiment. Pages that expanded and contextualised entities delivered far stronger gains. That aligns with what we saw in content audits. A precise Person entity attached to a thin, generic article does little. A precise Person entity attached to a well-sourced article, with visible biography, organisation link and topical expertise, gives systems multiple reinforcing signals.
Robby Stein, Google VP for Search, also highlighted a 2026 interface change in which AI Overview and AI Mode source links appear as “groups of links” that can “appear in a pop-up” as users hover. That kind of citation UX makes source clarity more visible to users, but it does not prove that schema caused the link. Treat benchmark data as directional evidence, not as a conversion funnel.
Policy, Spam, and the New Line Between Clarity and Manipulation
The new spam line is simple but uncomfortable: do not use technical structure to say something the page does not say. Google already prohibited hidden text, doorway pages, misleading structured data and other classic spam methods. In 2026, it also named attempts to manipulate generative AI responses. That pulls AI answer engineering into a familiar compliance frame.
There are obvious violations: hidden FAQ copy, white text on white backgrounds, font-size zero entity lists, fake author credentials, fake reviews and redirect behaviour that traps users. There are also subtle risks. A page that repeats answer-shaped language about a brand being the best choice across every FAQ can become recommendation poisoning if the editorial evidence does not support it. A review schema block that marks up aggregate ratings from a private CRM, with no visible user reviews, is another risk. A comparison page that treats one product as best across every metric without trade-offs is not editorial analysis. It is a policy liability.
The June 2026 back button hijacking enforcement is a useful reminder that technical SEO is not only about content. Google defined back button hijacking as behaviour that prevents users from returning to the previous page after pressing back, including redirect or reload loops. A publisher using WordPress snippets, ad scripts or history API experiments should test navigation after publish. Structured data can be clean while the page still violates spam policy through user experience interference.
For teams building an AI search strategy, the rule is to document reality. Schema should encode visible truth, not create a parallel page for machines.
Practical Entity Graph Blueprint for B2B Sites
A practical B2B blueprint starts with the homepage and works outward. Give the organisation one stable identity. Connect official social profiles through sameAs. Use a consistent logo URL. Add contactPoint only if the site provides supported contact routes. Connect the WebSite entity to the Organization where appropriate, but keep the homepage focused on the brand rather than dumping every possible property into one script.
Next, build author pages as real editorial assets. A Person page should include a visible biography, role, topical expertise, selected work, social or professional profiles and a clear connection to the publisher. In JSON-LD, the author should have a stable @id and worksFor relationship to the Organization. Each article should point to that same author ID. If the author leaves, do not delete the entity from historical articles. Update the author page honestly and preserve publication history.
Then connect commercial pages. Services should be Service entities with provider, serviceType, areaServed and visible offer details where available. Productised software pages can use Product and Offer when price and availability are public. Case studies can use Article or CreativeWork, not Product, unless they are actually product pages. Topic hubs can use CollectionPage or WebPage with ItemList where the list is visible and useful.
Finally, define a drift score. In our editorial workflow, I use three checks: visible claim parity, entity ID reuse and stale field detection. Visible claim parity asks whether every material structured claim appears on the page. Entity ID reuse checks whether the same author, brand and product IDs recur across templates. Stale field detection compares dateModified, price, author title and FAQ text against the live page. A page can pass syntax validation and fail all three editorial checks.
This is where crawl tools and content tools meet. A publisher reviewing AI SEO tools should ask not only which tool creates schema, but which tool catches schema drift after editors and developers change the site.
Technical Compliance Checks Before and After Publish
A schema implementation should end with a publishing checklist, not a code snippet. Before publication, validate JSON syntax, check rich result eligibility where relevant, inspect the rendered DOM, compare visible facts with JSON-LD, and crawl a sample of similar templates. After publication, retest live URLs rather than staging URLs because caching, minification, consent tools and ad scripts often differ between environments.
For WordPress sites, the specific post-publish checks are now more important than many teams realise. Press the browser back button after arriving from another page and confirm the browser returns immediately to the previous page. Inspect the DOM for text hidden with visibility hidden, display none, font-size zero, colour matching the background, or large negative absolute positioning. Some of those patterns can be legitimate for accessibility or responsive design, but hidden keyword, FAQ or entity blocks are a clear spam risk.
Performance bottlenecks also belong in the checklist. JSON-LD should not require a slow external request. Large Product graphs should not duplicate entire catalogues on every page. Client-side schema should not be injected so late that rendering tests miss it. Multiple plugins should not output conflicting Organization or Article blocks. When conflicts happen, choose one source of truth and disable duplicate output rather than trying to patch contradictions with additional properties.
The best operational rhythm is monthly crawl validation for small sites and weekly or deployment-triggered validation for large commerce or publishing sites. Teams with high-risk commercial claims should also version-control schema templates, so changes to price, review, author or legal properties can be reviewed before release.
Our Editorial Verification Process
This article was built as an explainer and technical guide, so our verification process combined official documentation, primary pricing pages, academic research and current search industry reporting. We cross-checked Google Search Central documentation for structured data, rich result validation, AI search guidance, spam policies and back button hijacking enforcement. We reviewed Schema.org documentation for vocabulary scope and supported formats. We checked official vendor pages for Yoast SEO Premium, Rank Math, Screaming Frog SEO Spider and WordLift before describing prices, features, integrations and usage limits.
For benchmark claims, we used 2026 research on AI Overviews, generative AI search source selection and structured linked data as a retrieval layer. We treated those studies as directional evidence rather than universal ranking rules because sample selection, query category, country availability and interface changes can materially affect results. For named industry statements, we used 2026 Google Search and I/O announcements, plus contemporaneous reporting on Sundar Pichai and Robby Stein comments about AI Overview quality and link presentation.
The live Perplexity AI Magazine sitemap endpoints were not accessible through our browsing tool during production, so internal links were selected from verified indexed Perplexity AI Magazine pages returned by search. We used eight semantically relevant AI search, AI Overview, GEO and SEO tool articles, and each internal link appears once in body sections only. No raw URLs are displayed in the article.
This article was researched and drafted with AI assistance and reviewed by the Awais Khalid editorial desk at Perplexity AI Magazine. All data, citations, pricing figures, and named quotes have been independently verified against primary sources before publication.
Conclusion
Schema markup for AI search is best understood as disciplined evidence design. It does not override Google quality systems, force AI Overview inclusion or guarantee that an assistant will cite a page. It can, however, make the important parts of a page easier to interpret: who wrote it, who published it, what product or service it describes, what the page is mainly about, and how those entities relate to the rest of the site.
The future question is not whether schema matters. It is which structured facts AI systems preserve as they crawl, clean, chunk and retrieve web content. That answer will vary by platform, interface and retrieval pipeline. Publishers therefore need a durable approach: accurate JSON-LD, visible evidence, stable entity IDs, honest author and product data, and routine drift checks.
The strongest schema programmes in 2026 will not look like growth hacks. They will look like editorial governance, technical QA and knowledge graph maintenance. That is slower than adding a plugin checkbox, but it is also safer, more defensible and more likely to survive the next change in AI search interfaces.
FAQs
What Does Structured Data Mean for AI Search?
Schema markup for AI search is structured data that helps machines understand visible page content, entities and relationships. It can clarify authors, organisations, products, services and article metadata. It does not guarantee inclusion in AI Overviews or chatbot answers.
Does Schema Markup Help AI Overviews?
Schema can support understanding and extraction, but Google says no special schema is required for generative AI search. Treat it as a clarity signal alongside helpful content, crawlability, authority, source quality and technical accessibility.
Which Schema Types Matter Most in 2026?
Most publisher and B2B sites should prioritise Organization, Person, Article or BlogPosting, Product or Service, BreadcrumbList where useful, and FAQPage only when visible FAQ content exists. LocalBusiness and HowTo are useful only when they match the page purpose.
Is JSON-LD Better Than Microdata for AI Crawlers?
JSON-LD is usually easier to maintain because it is separate from visible HTML attributes and fits modern CMS templates. Google supports JSON-LD, Microdata and RDFa for structured data, but JSON-LD is generally the cleaner operational choice.
Can I Add FAQ Schema Without Visible FAQs?
No. FAQPage markup should reflect visible questions and answers on the page. Adding hidden FAQ content for machines creates structured data quality risk and can cross into spam if used to manipulate search or AI responses.
How Do I Connect Authors to Organisations in Schema?
Create a stable Person entity for each author, include a worksFor relationship to the Organization entity, and reuse the same @id values across author pages and articles. Visible author biographies should support the structured data claims.
How Often Should Schema Be Audited?
Audit core templates after every deployment, then crawl high-value pages monthly for small sites and weekly for large publishing or ecommerce sites. Check syntax, visible claim parity, stale dates, prices, author roles and duplicate plugin output.
What Is the Biggest Schema Mistake for AI Visibility?
The biggest mistake is schema drift: structured data that no longer matches visible content. A page can validate technically while still presenting old prices, wrong authors, outdated logos or removed FAQ answers to machines.
References
- Google Search Central. (2026a). Introduction to structured data markup in Google Search. Google for Developers.
- Google Search Central. (2026b). Rich Results Test. Google Search Console Help.
- Google Search Central. (2026c). AI search guidance for website owners. Google for Developers.
- Google Search Central. (2026d). Spam policies for Google web search. Google for Developers.
- Google Search Central. (2026e). Back button hijacking policy enforcement. Google Search Central Blog.
- Schema.org. (2026). Schema.org documentation and vocabulary statistics. Schema.org.
- Reid, E. (2026). A new era for AI Search. Google Blog.
- Pichai, S. (2026). I/O 2026: Welcome to the agentic Gemini era. Google Blog.
- Volpini, A., Raad, J., Gamba, M., & Riccitelli, M. (2026). Structured linked data as a memory layer for retrieval-augmented generation. arXiv.
