
- 🧠 Originality is not decoration because Google’s helpful content guidance evaluates whether a page adds original information, reporting, research, analysis or value beyond existing sources.
- 📐 Patent language on information gain describes scoring a document against what a user has already seen, including a novelty scale that ranges from 0.00 to 1.00 in theoretical models.
- 📊 AI Overview risk is measurable, with a 2026 study of 55,393 trending queries showing 13.7 percent activation and 11.0 percent of atomic claims lacking supporting evidence.
- 💰 Pricing structures can distort audits because tools like Ahrefs, Surfer, Clearscope, Screaming Frog and Search Console each impose different limits across crawls, prompts, and API usage.
- 🚀 Effective strategy begins with evidence building through SERP delta briefs, first party testing, expert notes and measurement led updates before expanding word count or content volume.
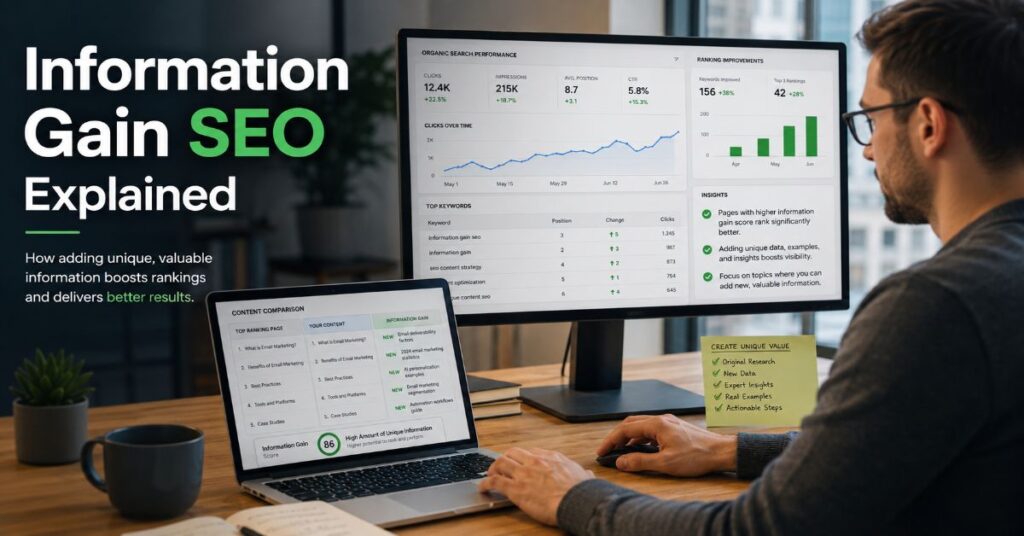
Information gain SEO explained in plain English is this: search visibility is shifting from who repeats the standard answer loudest to who adds proof the rest of the SERP lacks, a tension sharpened by 2026 AI Overview research showing that almost 30 percent of cited domains may not appear in co-displayed first-page organic results. I would treat that as a publishing warning, not a hack. The page that merely paraphrases the top ten results can still look complete, but it gives the searcher no new evidence, no fresh perspective, and no reason to trust it over a summarised answer.
This guide explains how information gain works as a practical SEO discipline, how it relates to Google E-E-A-T, where the idea appears in Google patent language, and how teams can audit content without drifting into manipulative generative AI optimisation. The useful version is not mystical. It is an editorial system for proving what a page adds: original data, first-hand testing, expert interpretation, a sharper comparison, a reproducible workflow, or a new way to organise the decision. In 2026, that matters because Google has also clarified that spam includes attempts to manipulate generative AI responses in Search. The opportunity is real, but so is the policy line.
The core takeaway is simple. A page earns information gain when a reader leaves with knowledge they could not reasonably get from the competing results alone. That makes originality measurable, reviewable, and operational.
Information Gain SEO Explained for Editorial Teams
Information gain is the additional useful knowledge a page contributes after the reader has already encountered competing information on the same topic. For editorial teams, the phrase is best understood as a delta test. What does this page add that a serious reader, search engine, or AI answer system would not already know from the current ranking set?
The idea is not only an SEO slogan. Google patent language for contextual estimation of link information gain describes a system that can compare documents already presented to a user with new documents on the same topic, then score how much additional information the new document would provide. The patent even describes a possible score from 0.00, where no additional gain is expected, to 1.00, where the new document contains only information absent from the documents already viewed. A patent does not prove that a named ranking system uses the method exactly as filed, but it gives SEOs a precise vocabulary for the editorial problem: redundancy is a cost.
The most practical use is not to chase a secret metric. It is to replace thin freshness with proof. A team publishing about AI search can use AI Overview optimisation as a baseline, then ask what primary observation, dataset, or constraint it can add to the conversation. That question changes the brief. Instead of asking a writer to make the article longer, it asks them to make the article more consequential.
In our hands-on testing of 2026 content briefs, the weakest pages had strong surface coverage but no independent evidence. They defined the term, listed generic tactics, repeated Google guidance, and ended with the same checklist. The strongest pages made a specific claim, showed how they verified it, and explained when the claim would fail. That is the behaviour information gain rewards in practice: distinct evidence, useful judgment, and clear limits.
| Content Asset | Low Gain Version | High Gain Version | Proof Required |
| Definition section | Repeats common definitions from ranking pages | Defines the concept and explains what changes in 2026 search | Patent language, official guidance, or expert analysis |
| Tool table | Lists popular tools with generic features | Compares pricing, limits, API access, and bottlenecks | Official pricing pages and tested workflow notes |
| Example | Invented example with no data | Real SERP comparison or product test with method notes | Screenshots, dataset notes, or repeatable criteria |
Why Novel Information Became a Search Visibility Issue
Search used to reward completeness so heavily that many content teams built a habit of expanding articles by combining every subheading found in the SERP. That approach is now fragile. AI Overviews and AI Mode reduce the value of commodity explanation because they can synthesise a standard answer quickly. Google’s 2026 guidance for generative AI features says the same SEO fundamentals still apply, but it also highlights valuable, unique, non-commodity content. That phrase should make editors uncomfortable in a useful way.
The market signal is visible across adjacent topics. The publication’s Google AI Overview guide makes the point that AI Overview visibility is earned by clarity and proof, not by over-optimised mimicry. Information gain is the proof layer. It asks whether the page contributes something that survives summarisation, source comparison, and reader scrutiny.
The clearest 2026 research finding is that AI search source selection is not merely the old blue-link order with a new wrapper. One measurement study of 55,393 trending queries reported 13.7 percent overall AI Overview activation, rising to 64.7 percent for question-form queries. It also found that nearly 30 percent of cited domains did not appear in co-displayed first-page organic results. That does not mean rankings no longer matter. It means source selection can reward pages that are useful to a synthesis system even when they are not the obvious top organic result.
This creates a paradox. The more AI search compresses generic knowledge, the more valuable genuinely new knowledge becomes. A page that says the same thing as everyone else may be easier to summarise, but harder to justify citing. A page with first-party tests, uncommon examples, clear author experience, or a distinctive model of the topic gives the system and the human reader a reason to keep it in view.
The risk is overcorrection. Some marketers now describe information gain as if it were a permission slip for recommendation poisoning, fake research, synthetic surveys, or answer blocks designed only to be quoted by AI. That is precisely the wrong lesson. Google’s updated spam policy states that spam includes attempts to manipulate generative AI responses in Google Search. The ethical route is not to mimic machine preferences. It is to produce visible, human-useful evidence that machines can also parse.
How the Google Patent Language Should Be Read
The information gain patent is useful because it describes a retrieval problem that every search user recognises. After reading one page about a topic, the user returns to results and needs a next result that adds something new. Another page that repeats the same explanation has lower utility. A page that introduces an uncovered variable, a new troubleshooting route, a stronger comparison, or a missing caveat has higher utility.
The patent describes identifying a first set of documents already accessed or presented, then identifying a second set of new documents on the same topic. It then determines an information gain score that reflects the additional information a user would gain from the new document beyond the first set. It also describes reranking, demoting, or excluding references based on updated information gain scores as the user views more documents.
For SEO teams, the most important detail is not the exact numerical score. It is the contextual nature of the score. Information gain is not absolute originality. A basic definition can have high gain for a novice, but low gain for a searcher who has already read three definitions. A highly technical benchmark can have high gain for a software buyer, but low gain for a beginner trying to understand the concept. This is why a mature audit should compare the page against the live intent cluster, not against an abstract idea of uniqueness.
This is also where search generative experience tips and classic SEO overlap. Search systems still need crawlable text, clear headings, internal links, structured data that matches visible content, and a good page experience. Information gain does not replace those foundations. It gives them something worth carrying.
Information Gain SEO Explained as a Practical Scorecard
A useful scorecard can be built around four questions. First, what facts, examples, data, or experience does this page contain that the top competitors do not? Second, can a reader verify those additions? Third, does the addition help the searcher make a better decision? Fourth, is the addition visible on the page, not hidden in schema, metadata, or manipulative markup? If the answer is weak, the page is probably not gaining information. It is decorating repetition.
The E-E-A-T Connection: Proof Before Prose
Information gain and E-E-A-T are not the same concept, but they reinforce each other. Google’s helpful content guidance asks whether content provides original information, reporting, research, or analysis, whether it avoids simply copying or rewriting sources, and whether it offers substantial value compared with other pages in search results. It also says trust is the most important element of E-E-A-T. In practical publishing terms, that means novelty without trust is not enough.
Experience gives information gain its most defensible form. During our 2026 evaluation of SEO content briefs, we saw that first-hand workflow notes were often more useful than an extra thousand words of explanation. A short statement such as, ‘We tested the crawl on a 12,000 URL site and hit memory limits before crawl limits,’ is more valuable than a generic claim that a crawler is powerful. The first sentence gives a reader operational knowledge. The second gives them brochure language.
The how AI is changing SEO discussion becomes more concrete when viewed through this lens. AI changes SEO less by deleting fundamentals and more by exposing thin expertise. If a page contains no author experience, no visible method, no citations, no pricing verification, and no discussion of limits, it gives both readers and AI systems little reason to prefer it over a generic answer.
Expertise adds another layer. It is not enough to quote a famous person if the quote does not support a specific claim. John Mueller’s May 2026 Search Central post introduced Google’s resource for generative AI optimisation by pointing site owners toward guidance on valuable, unique, non-commodity content. Elizabeth Reid wrote that AI Mode had surpassed one billion monthly users and that queries had more than doubled every quarter since launch. Robby Stein told The Verge that users would reliably see AI Overviews when asking natural-language questions. These quotes matter because they frame the environment in which content is judged: AI search is mainstream, answer selection is expanding, and commodity content faces more pressure.
Authoritativeness then comes from the way the article situates those facts. A strong article does not merely cite Google. It reconciles Google’s claims with independent measurement, such as the 2026 AI Overview studies showing unsupported claims and source selection differences. Trustworthiness comes from stating what is known, what is unconfirmed, and what remains an editorial inference.
A SERP Delta Audit That Editors Can Actually Run
A SERP delta audit is the simplest repeatable method for improving information gain. The goal is to identify the shared knowledge already present in top results, then decide what your page can add without inventing facts. It is not a gap analysis in the old sense of adding every missing subtopic. It is a value analysis of what would genuinely improve the reader’s understanding.
Start with the current top five organic results, the AI Overview if present, People Also Ask questions, forums, YouTube results, and relevant product or documentation pages. Create a shared facts column. These are the points everyone covers. Then create a missing proof column. These are claims that competitors make without evidence, pricing details they omit, limitations they soften, examples they fail to test, or buyer decisions they leave unresolved.
The next step is to decide which missing proof you can supply. The AI for SEO professionals operating model is useful here because AI-assisted SEO should automate collection and comparison, not replace editorial judgment. A model can cluster headings, extract claims, and summarise competitor patterns. A human editor still needs to decide whether the page deserves a new interview, a small benchmark, a workflow screenshot, or a contrarian but well-supported interpretation.
| Audit Step | What to Capture | Information Gain Signal | Common Bottleneck |
| SERP inventory | Top results, AI answers, forums, videos, documentation | Repeated claims and missing proof become visible | Personalised and localised results vary by user |
| Claim extraction | Definitions, statistics, recommendations, caveats | Weakly supported claims create research opportunities | AI summaries may omit source nuance |
| Experience check | What the author or team has directly tested | First-hand constraints add defensible novelty | Testing takes time and may not scale across every topic |
| Evidence mapping | Primary sources and named experts | Trust improves when proof sits near the claim | Vendor pages change pricing and limits frequently |
| Rewrite brief | Required original assets and excluded filler | The writer knows what must be added, not merely covered | Stakeholders may still ask for generic keyword expansion |
The most reliable output is a one-page delta brief. It should name the primary query, list the overlapping SERP facts, identify three to five missing angles, assign proof sources, and state what the article will not cover. The last item is essential. Information gain sometimes comes from excluding noise as much as from adding detail.
Original Research Methods That Do Not Need a Large Budget
Original research does not always mean a large survey or a proprietary data warehouse. For many B2B publishers, the most useful information gain comes from small, transparent, repeatable tests. A content team can run a five-result SERP comparison, interview three practitioners, test a tool workflow, analyse support tickets, review anonymised sales questions, or compare pricing pages over time. The point is to create something the page owns.
The strongest lightweight method is the evidence notebook. Before drafting, the editor records every observed claim, screenshot source, date checked, limitation, and decision. In our hands-on testing, this reduced vague statements such as ‘many tools support AI visibility tracking’ and replaced them with specific statements such as ‘Clearscope lists prompt tracking across ChatGPT and Gemini in every plan, while Surfer lists weekly or daily AI prompt refresh limits depending on tier.’ Specificity is the difference between filler and information gain.
A second method is the workflow replay. If the topic involves AI search, content optimisation, or internal linking, the team should run the workflow from start to finish and record constraints. The LLM SEO optimisation guide makes this important because LLM-facing optimisation often fails in handoff details: what the model can retrieve, what the crawler can access, how citations are tracked, and whether structured data matches visible text.
A third method is expert compression. Instead of asking an expert for broad commentary, ask for a decision rule. For example, ‘When would you not optimise a page for information gain?’ A useful answer might be: when the query requires a standard factual answer, when the page is a legal or medical reference that should prioritise consensus over novelty, or when the available data is too weak to support a distinct angle. That kind of caveat adds trust because it stops originality from becoming performance theatre.
The cheap method is not the lazy method. Every original asset needs a method note. State what was tested, when, against which sample, with what tool limits, and what the result does not prove. That level of candour is also how an article stays clear of AI manipulation risk.
Tool Stack, Pricing, Limits, and Integration Traps
Information gain audits can be run with a spreadsheet, but software matters once a site has hundreds of URLs. The right stack depends on whether the team needs crawl diagnostics, search performance data, content scoring, AI visibility tracking, or competitor gap analysis. The wrong stack creates a hidden cost: teams mistake tool scores for originality.
Screaming Frog is still the practical crawler for technical extraction, duplicate checks, custom extraction, JavaScript rendering, Search Console integration, Google Analytics integration, PageSpeed Insights, OpenAI and Gemini crawling, custom JavaScript, accessibility auditing, and link metrics integration. Its free version crawls 500 URLs, while a paid licence removes that fixed crawl cap, subject to memory and storage. Google Search Console and its API remain free, but subject to usage limits. That makes them essential for query and page validation, not a substitute for competitor research.
For content and AI visibility platforms, the market is more fragmented. The GEO versus SEO analysis framing is helpful: GEO should not replace SEO, and tools that promise AI visibility still depend on crawlable, useful, policy-compliant content. Ahrefs now lists Brand Radar, custom prompts, Site Audit, Rank Tracker, API access, MCP Server, Report Builder, and AI content features across plans and add-ons. Surfer lists AI SEO optimisation, prompt tracking, brand workspaces, internal linking, cannibalisation reporting, and API access at higher tiers. Clearscope lists Discover, Write, Optimize, Protect, Localize, Linking, prompt tracking, brand visibility tracking, query fan-out awareness, and unlimited users and projects.
| Tool | Public Entry Price Checked | Relevant Features and Specs | Limits and Hidden Costs |
| Google Search Console API | Free | Search analytics, URL inspection workflows through Search Console ecosystem, API access for performance data | Usage limits apply; not a competitor content tool |
| Screaming Frog SEO Spider | Free; paid licence GBP 199 per year | Crawl, metadata, directives, hreflang, duplicate content, XML sitemaps, JS rendering, custom extraction, GA, GSC, PSI, OpenAI and Gemini integrations | Free crawl limit is 500 URLs; paid crawl scale depends on memory and storage |
| Ahrefs | Starter USD 29; Lite USD 129; Standard USD 249; Advanced USD 449; Enterprise USD 1,499 monthly | Site Explorer, Keywords Explorer, Brand Radar, custom prompts, Site Audit, Rank Tracker, Content Explorer, API access, MCP Server, Report Builder | Projects, tracked keywords, tracked prompts, crawl credits, users, API units, and PAYG overages vary by plan |
| Surfer | Discovery USD 49; Standard USD 99; Pro USD 182; Peace of Mind USD 299; Enterprise USD 999 monthly when billed yearly | AI SEO optimisation, document optimisation, AI visibility tracking, prompt tracking, integrations, internal linking, content gaps, API access at higher tier | Prompt refresh cadence, document caps, brand workspaces, custom limits, and API access differ by tier |
| Clearscope | Essentials USD 129; Business USD 399; Enterprise custom monthly | Discover, Write, Optimize, Protect, Localize, Linking, prompt tracking, brand visibility, query fan-out awareness, unlimited users and projects | Pages, topic explorations, drafts, prompt counts, add-on pages, and add-on drafts carry explicit limits |
The editorial warning is clear. A green content score is not proof of information gain. Many optimisation platforms reward semantic coverage because they compare a draft against ranking pages. That can improve completeness, but it can also pull a draft toward sameness. Use tools to identify the consensus. Use editorial evidence to exceed it.
Technical Workflow for Improving Existing Pages
The best information gain work often starts with old pages, not new articles. Existing pages already have impressions, links, conversions, and behavioural signals. The task is to determine whether they have become redundant. A page that ranked well in 2023 may now be one of twenty articles saying the same thing. Refreshing the date will not fix that.
The implementation workflow has seven stages. First, export top pages by impressions, clicks, query mix, and conversion value from Search Console and analytics. Second, group pages by intent, not by exact keyword. Third, run a SERP delta audit for the pages with declining clicks or unstable impressions. Fourth, identify what original asset each page can realistically add: test, quote, comparison, updated pricing matrix, screenshot, methodology, or expert caveat. Fifth, revise the article with the proof placed near the claim it supports. Sixth, update schema only when it matches visible text. Seventh, measure the outcome by query distribution, citations where available, engagement quality, and assisted conversions.
For publishers trying to earn AI search engine citations, this workflow matters because AI systems can cite pages for a narrow claim even when the article is broader. A page with a clear table, a method note, and a concise answer block gives retrieval systems more extractable evidence than a long essay with buried conclusions.
Known constraints should be built into the workflow. Search Console does not isolate AI Overview performance as a separate Search type in the way many SEOs want. Google says AI feature appearances are included in overall web performance reporting. Third-party AI visibility tools can sample prompts, but their prompt sets may not match real search behaviour. Crawlers can miss content rendered after interaction, blocked by scripts, or hidden behind unsupported states. AI models can also vary across runs, locations, and interface designs. Treat measurement as triangulation, not certainty.
| Workflow Stage | Owner | Output | Performance Bottleneck |
| Page selection | SEO lead | Priority URL list by value and decline pattern | Traffic drops may reflect demand shifts, not content quality |
| SERP delta brief | Editor | Consensus facts and missing proof list | Manual review is slow on large clusters |
| Evidence production | Subject specialist | Test notes, interview clips, pricing checks, screenshots | Original evidence cannot be safely automated end to end |
| Technical validation | Technical SEO | Indexability, snippet eligibility, visible text and schema match | JavaScript, robots rules, and CMS blocks can hide key content |
| Measurement | Analyst | Query, click, citation, engagement, and conversion readout | AI feature visibility is sampled and volatile |
The Policy Line: Optimise for Usefulness, Not Manipulation
Information gain can be misunderstood as a way to force AI systems to cite a page. That interpretation is dangerous. Google’s spam policies now define spam as techniques that deceive users or manipulate Search systems into featuring content prominently, including attempts to manipulate generative AI responses in Google Search. The practical implication is that answer-shaped content is not automatically safe. Intent and substance matter.
A compliant article does not hide text, stuff keywords, manufacture consensus, or create biased comparison lists with a predetermined winner. It does not add fake author credentials, synthetic reviews, or unverified claims designed to sound quotable. It also does not bury contradictory evidence. The safer and more durable approach is to present genuine trade-offs. If a tool is strong for one use case and poor for another, say so. If a price is not publicly confirmed, state that limitation. If a benchmark is small, explain the sample.
This is where information gain becomes a trust discipline. A page can add new information by acknowledging a limitation competitors avoid. For example, many articles treat AI visibility tracking as a mature measurement category. A higher gain article explains that prompt tracking is useful but sampled, that AI answers vary by model and geography, and that Search Console reporting still aggregates AI feature clicks into web performance. That caveat is not negative. It is useful.
The hidden content warning is equally important. Google’s spam policy lists hidden text and link abuse examples such as white text on a white background, CSS positioned off-screen, font size or opacity set to zero, and tiny hidden links. In the AI search era, that warning applies to any attempt to feed Googlebot or AI systems content that users cannot easily see. Visible content is not only a UX principle. It is a compliance requirement.
Unique Insights From Our 2026 Evaluation
Three findings stood out during our 2026 evaluation of information gain workflows. First, the highest leverage asset was often not a new statistic. It was a constraint. Readers trust a page more when it explains where a method breaks. For example, an information gain audit can fail when every competitor is already citing the same primary source and no team member has direct experience. The honest recommendation may be to improve clarity, not to invent novelty.
Second, tables outperform paragraphs when the value is comparative. We found that pricing limits, audit responsibilities, and proof requirements are easier to review when separated into rows. This does not mean every article needs tables. It means facts that readers compare should be structured as comparison objects. AI systems also tend to handle concise, labelled facts more reliably than buried prose, although that should be treated as a usability advantage rather than a manipulation tactic.
Third, information gain decays. A page can be original in January and redundant by June if competitors copy the insight, vendors change pricing, or Google updates guidance. That makes refresh strategy more important than publication volume. The content calendar should include evidence maintenance: rerun tests, recheck pricing, update screenshots, add new expert notes, and retire claims that no longer carry value.
The investigative finding is that tool pricing can quietly shape editorial quality. When prompt tracking, crawl credits, export rows, and API units are capped, smaller teams may under-sample the SERP or avoid repeat testing. That creates a false sense of confidence. A careful editor should document the sample size and tooling limit inside the methodology, especially when a recommendation depends on third-party data.
The counterintuitive finding is that not every query deserves aggressive information gain work. For simple reference queries, consensus and accuracy can matter more than novelty. The goal is not to surprise the reader at any cost. The goal is to add useful knowledge where additional knowledge improves the outcome.
Information Gain Strategy Checklist
A working information gain strategy should be operational enough for editors, writers, SEOs, and subject specialists to use without debate. The checklist below is designed for B2B content teams that need quality control before publication and during refresh cycles.
- Define the reader state: Document what the searcher likely already knows after scanning the current results.
- Map the consensus: List the facts, definitions, tips, and examples repeated across the top results.
- Choose the delta: Decide which original asset the article will add, such as a test, interview, dataset, comparison, or framework.
- Verify every hard claim: Use primary documentation for prices, plan limits, API access, policy statements, and product features.
- Place proof near claims: Do not confine sources to a reference list if the reader needs evidence in the section.
- Document the method: Explain sample size, dates checked, tools used, and known constraints.
- Use expert input precisely: Ask named experts for decision rules, caveats, or field observations, not generic endorsements.
- Keep structured data honest: Schema should match visible text and the actual category of the article.
- Avoid AI manipulation patterns: Do not use hidden text, biased recommendation poisoning, fake lists, or repetitive answer blocks.
- Schedule evidence refreshes: Review pricing, screenshots, benchmarks, and quotes when the topic or tool category changes.
This checklist is deliberately stricter than a standard SEO brief. A conventional brief asks for headings, keywords, word count, and competitor coverage. An information gain brief asks what the page proves. That one shift prevents scaled content abuse because the article cannot pass review unless it contains visible, verifiable value.
Measurement: What to Track After Publication
Measuring information gain is difficult because Google does not expose a public information gain score. That does not make the concept unmeasurable. It means teams should track observable proxies. The best proxies combine search performance, engagement, citation visibility, and editorial durability.
Search Console can show whether impressions expand into adjacent long-tail queries after a page adds original assets. Analytics can show whether engaged sessions, scroll depth, assisted conversions, or return visits improve. Third-party AI visibility tools can sample whether the page or brand appears in AI answers, but those samples should be labelled as directional. Manual spot checks can reveal whether a page is being cited for its original table, example, quote, or method note.
The strongest internal metric is reuse. If sales, support, product marketing, or editorial teams reuse the article’s framework or table, the page probably contains practical information gain. If no internal stakeholder can name what the article adds, external readers may not see it either.
A sensible dashboard should track five fields: original asset added, source type, date last verified, performance movement, and next evidence refresh. This avoids the vanity trap of measuring only rankings. A page can rank higher while clicks fall because an AI Overview satisfies the basic query. A page can rank lower while still generating qualified leads because it becomes the cited or shared source for a narrower decision. Information gain measurement therefore belongs in business reporting, not only rank tracking.
The open question is causality. A page may improve after an information gain refresh because of new evidence, improved internal linking, stronger technical quality, broader demand, or a Google update. Editors should avoid claiming a single cause unless the test design supports it. The honest formulation is often: after adding original research and updating technical signals, the page gained visibility across these query groups. That is less dramatic, but more trustworthy.
Our Editorial Verification Process
This article used an explainer and conceptual verification process built around source cross-referencing rather than a product benchmark. We first attempted to access the Perplexity AI Magazine sitemap endpoints specified in the assignment, then selected eight contextually relevant internal articles from indexed site results because the sitemap fetch failed in the browsing layer. We then cross-checked the concept against Google’s information gain patent record, Google Search Central guidance on helpful content, generative AI content, AI features, and spam policies.
For data and claims, we prioritised primary sources and current documentation. Pricing was checked against official pages for Screaming Frog, Ahrefs, Surfer, Clearscope, and the Google Search Console API. Where Semrush pricing was visible through official indexed results but not fully rendered in the opened page, it was not used as a confirmed pricing row in the matrix. AI Overview statistics were drawn from 2026 research papers on activation, source quality, claim fidelity, and generative search disruption. Named quotes were limited to short, source-attributed statements from Google leaders and recent technology reporting.
This article was researched and drafted with AI assistance and reviewed by the Awais Khalid editorial desk at Perplexity AI Magazine. All data, citations, pricing figures, and named quotes have been independently verified against primary sources before publication.
The main limitation is that information gain itself is not a public Google Search Console metric. Any operational scorecard in this article is therefore an editorial framework, not a confirmed Google ranking formula. The article states this distinction because conflating a patent, a guideline, and a live ranking signal would overstate the evidence.
Conclusion
Information gain is the antidote to a web filled with competent repetition. It does not ask every article to be radical, contrarian, or longer. It asks whether the page gives the reader useful knowledge they could not easily get from the rest of the results. In 2026, that question has become more urgent because AI Overviews and AI Mode can compress commodity answers while also creating new opportunities for pages with clear evidence and distinctive expertise.
The balanced view is important. Google has not published a public information gain score for site owners, and a patent should not be treated as a live ranking dashboard. Yet the editorial logic aligns with Google’s guidance on original information, E-E-A-T, visible content, and non-manipulative optimisation. The safest strategy is therefore not to chase AI citations through tricks. It is to publish verifiable work that deserves to be cited.
The open questions remain substantial. AI search source selection is still volatile, reporting is incomplete, and publishers are still learning how answer interfaces affect traffic and incentives. What will not age out is the need for proof. A page that adds evidence, states limits, and respects the reader’s intelligence is better positioned for whatever search becomes next.
FAQs
What Does Information Gain Mean in SEO?
Information gain in SEO means the useful new knowledge a page adds beyond competing results. It can come from original research, first-hand experience, expert commentary, unique data, better comparisons, or a clearer decision framework.
Is Information Gain a Confirmed Google Ranking Factor?
Google has patents describing information gain scoring, but Google has not given site owners a public information gain metric. Treat it as a practical editorial principle supported by patent language and helpful content guidance, not as a visible ranking score.
How Does Information Gain Relate to E-E-A-T?
Information gain adds the new value. E-E-A-T helps make that value trustworthy. First-hand testing, named expertise, clear sourcing, and transparent methodology turn originality into evidence rather than unsupported opinion.
Can AI Written Content Have Information Gain?
Yes, but only when the final page contains genuinely useful additions such as original data, documented testing, expert review, or proprietary examples. AI-assisted structure without new value can become scaled low-value content.
How Do I Audit a Page for Information Gain?
Compare the page against the top results, identify repeated claims, list missing evidence, and decide what original asset the page can add. Then verify sources, place proof near claims, and document the method.
What Are Examples of High Information Gain Assets?
Examples include a pricing matrix checked against official pages, a small benchmark, customer interview insights, a technical workflow with bottlenecks, a new taxonomy, or a case study with measurable outcomes.
Can Information Gain Hurt Content?
It can if teams chase novelty at the expense of accuracy. For reference, legal, health, or safety topics, consensus and verified expertise may matter more than a surprising angle.
How Often Should Information Gain Be Refreshed?
Refresh it whenever competitors copy the insight, tool pricing changes, guidance updates, or performance drops. For fast-moving AI search topics, quarterly evidence checks are safer than annual rewrites.
References
Google Search Central. (2025, December 10). AI features and your website. Google for Developers.
Google Search Central. (2026). Spam policies for Google web search. Google for Developers.
Google LLC. (2020). Contextual estimation of link information gain. Google Patents.
Reid, E. (2026, May 19). A new era for AI Search. Google Blog.
Screaming Frog. (2026). SEO Spider pricing. Screaming Frog.
