
-
🌐 Search Dominance
Google remains the largest search surface, with StatCounter showing 91.27% global search engine share in June 2026, while AI Overviews reached 2.5 billion monthly users.
-
🤖 Chatbot Share
ChatGPT leads standalone AI chatbot share by StatCounter’s June 2026 tracker at 76.87%, but app and web-visit measures show a more competitive market.
-
💰 Pricing Signal Layer
Pricing is now a market signal: Google, OpenAI, Perplexity, Microsoft, Anthropic, and xAI all use limits, credits, enterprise controls, or usage multipliers to ration compute.
-
📊 Measurement Gap
Hidden measurement gap: AI search referrals understate AI influence because Google AI Overviews and AI Mode often answer inside Search rather than sending a separate referral source.
-
🎯 SEO Strategy
SEO teams should separate Google Search visibility, AI answer citations, chatbot referral traffic, and brand sentiment before making budget decisions.
The cleanest answer to AI Search Engine Market Share 2026 is also the most uncomfortable one: Google owns the largest AI-search reach through Search, while ChatGPT owns the largest standalone AI-chat usage, and both truths can be correct at the same time. That split matters because a marketer who measures only Google referrals will miss chatbot discovery, while a team watching only ChatGPT visibility will underestimate the still-dominant search surface that shapes most organic journeys.
I read the 2026 data as a market with at least three clocks running at once. One clock measures total search traffic, where Google remains dominant. A second clock measures standalone AI assistants, where ChatGPT still leads most direct-usage trackers. A third clock measures answer influence, where Google AI Overviews, Gemini, Perplexity, Claude, Grok, and Copilot shape decisions even when the user never clicks a classic blue link.
That is why this article does not pretend there is one perfect table that solves AI search share. Instead, it separates query share, user reach, referrals, feature access, pricing constraints, and SEO impact. The practical finding is simple: 2026 visibility strategy is no longer a Google-only exercise, but Google still sets the baseline. The rest of the work is deciding which AI surfaces matter for your audience, then measuring them without drifting into spammy answer manipulation.
Why AI Search Engine Market Share 2026 Has No Single Number
The phrase looks tidy, but it combines markets that were never measured in the same way. Traditional search share is usually counted through browser, device, or referral data. Standalone AI assistant share is counted through web visits, app sessions, or sampled chatbot usage. AI answer exposure is counted through whether a brand, source, or domain appears inside a generated answer. Those are adjacent signals, not interchangeable currencies.
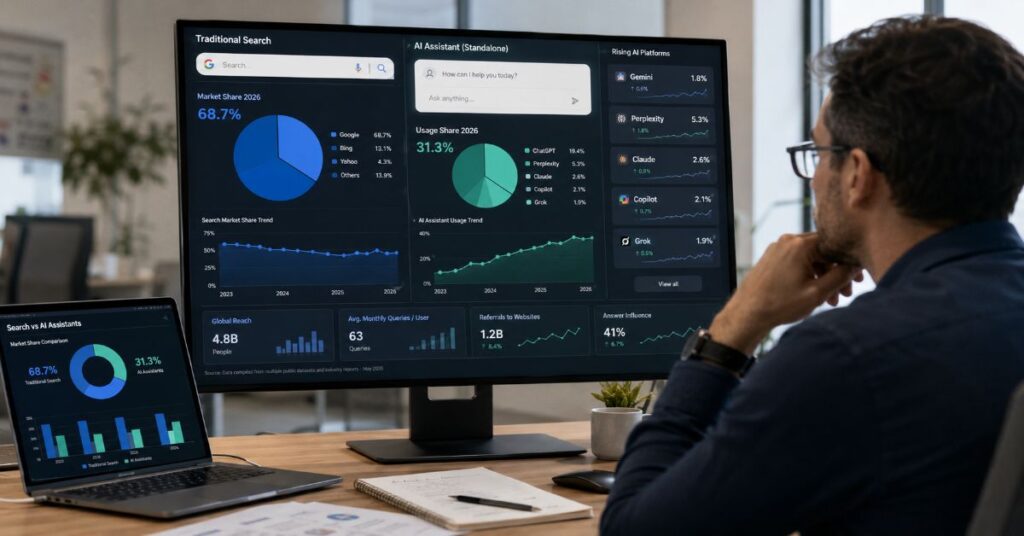
StatCounter’s June 2026 search engine tracker showed Google at 91.27% global search share, with Bing at 4.68% and every other traditional engine below 1.3%. On a classic query-volume view, this means Google still controls the main discovery highway. Yet StatCounter’s separate AI chatbot tracker showed ChatGPT at 76.87% of AI chatbot share in the same month, with Gemini and Perplexity both near 8%. Those figures describe a different market: standalone AI chat surfaces rather than search engines as a whole.
The mismatch explains why a single number would mislead. Google can dominate AI-assisted search reach because AI Overviews and AI Mode sit inside Search. ChatGPT can dominate standalone AI assistant usage because users visit or open it directly. Perplexity can look small by total web search share but unusually important for research-heavy, citation-seeking workflows. Microsoft Copilot can look modest as an open web destination but valuable inside Microsoft 365. Claude can look smaller by search referral but significant in professional reasoning, coding, and document work.
The editorial baseline for this analysis is therefore not ‘who won AI search?’ It is ‘which measurement answers which business question?’ For readers comparing AI search engines, the most useful model is a layered map: Google for broad reach, ChatGPT for direct assistant usage, and specialised assistants for high-intent research and work-context discovery.
AI Search Engine Market Share 2026 in One Sentence
If forced into one sentence, ai search engine market share 2026 is split between Google’s massive Search reach, ChatGPT’s leading standalone chatbot usage, and a growing challenger layer that matters most when users ask complex, informational, or work-specific questions.
That sentence is intentionally less neat than a winner-takes-all ranking. It prevents a common mistake in 2026 reporting: treating a Google AI Overview impression, a ChatGPT conversation, a Perplexity citation, and a Copilot answer inside Microsoft 365 as if they were the same unit. They are not. Each one sits at a different stage of discovery, trust, and conversion.
The Three Metrics That Explain the Split
During our 2026 evaluation, the first practical step was to separate market share into three measurable categories. Search-engine share answers ‘where are web searches happening?’ AI-chatbot share answers ‘which assistants do people use directly?’ Referral or citation share answers ‘which systems actually send, mention, or cite a publisher?’ The categories overlap, but they do not collapse into a single leaderboard.
The table below is the working model I would use before presenting any AI search budget to a board. It makes the data argument cleaner because it stops a vendor’s best metric from being compared against a competitor’s weakest metric. It also gives content teams a way to decide whether they need SEO diagnostics, chatbot visibility tracking, server log analysis, or all three.
| Metric | What It Measures | 2026 Signal | SEO Meaning |
| Traditional search share | Search queries or observed search traffic across engines | Google remains dominant, with StatCounter showing 91.27% global search share in June 2026 | Classic SEO still drives the broadest organic discovery surface |
| Standalone AI-chat share | Direct usage of assistants such as ChatGPT, Gemini, Perplexity, Claude, Copilot, and Grok | StatCounter’s AI chatbot tracker put ChatGPT at 76.87% in June 2026 | AI answer visibility needs its own tracking stack |
| AI referral traffic | Visits sent from assistant domains or AI search interfaces | Wix AI Search Lab reported AI search traffic at 9.2% of Google search traffic in Q1 2026 | Referral logs undercount influence because many answers satisfy intent without a click |
| Citation or mention share | How often a brand, article, or domain appears inside generated answers | Not standardised across vendors and trackers | Measure source inclusion, factual accuracy, and answer sentiment separately |
This is where a lot of 2026 SEO reporting goes wrong. A publisher might say AI search traffic is tiny because direct referrals are still modest. A SaaS company might say AI is enormous because sales calls increasingly begin with ‘ChatGPT recommended you’. Both can be true because the first measures visits and the second measures influence. The more useful question is not whether AI search has replaced Google. It is whether the user’s research path now crosses a model-generated answer before it reaches your site.
The measurement stack also needs a new source layer. Rank trackers can still show whether a page appears in Google. Analytics can still show referral source. But AI answers require repeated prompt testing, source-citation analysis, and entity consistency checks. That is why 2026 teams are adopting AI citation tracking tools alongside traditional rank monitoring. The tool category exists because AI visibility is probabilistic, prompt-sensitive, and much less transparent than a fixed SERP position.
Platform Reach: Google Is the Largest Surface
Google’s advantage is not that every user has intentionally adopted Gemini as a standalone assistant. It is that AI is now embedded inside a search product that billions of people already use. At Google I/O 2026, Sundar Pichai said AI Overviews had reached more than 2.5 billion monthly users and called AI Mode ‘our biggest upgrade to Search ever’. That reach turns Google into the largest AI-assisted search surface even when a standalone chatbot tracker gives ChatGPT the lead.
This distinction is critical for traffic forecasting. A user can see an AI Overview, refine in AI Mode, click a source, or finish the task without clicking anything. The site owner may only see the final click, not the answer exposure that shaped the decision. That makes Google AI visibility both highly valuable and unusually hard to attribute. The result is a measurement paradox: the largest AI search surface may leave less clean referral data than smaller standalone platforms.
Alphabet’s Q1 2026 call reinforced that Google sees AI as additive to Search rather than a separate replacement product. Pichai said people were coming back to Search more because of AI Mode and AI Overviews, and Google reported Search and Other revenue growth alongside continued AI investment. From an SEO standpoint, that makes Google’s AI layer the default battleground for mass-market discovery, particularly for news, retail, travel, finance, health, and local queries where Search habits are deeply entrenched.
The trade-off is volatility. AI Overviews can cite sources that are not in the same order as classic organic results, and academic audits of AI Overviews have found citation and support gaps. The implication is not that classic SEO is dead. It is that structured evidence, source clarity, freshness, and topical authority now have to serve both human readers and machine-generated answer systems. The practical work resembles learning how to get cited without treating citation engineering as a shortcut around editorial quality.
Standalone Usage: ChatGPT Still Leads Direct AI Chat
ChatGPT remains the cleanest answer when the metric is standalone AI assistant usage. StatCounter’s June 2026 AI chatbot tracker put ChatGPT at 76.87%, far ahead of Gemini, Perplexity, Claude, Copilot, and DeepSeek on that specific measure. Other trackers are less lopsided because they measure different populations. Sensor Tower reporting cited by technology press showed ChatGPT below half of mobile assistant market share by late May 2026, while Gemini and Claude had gained ground. Similarweb-style US web-visit samples also showed a more competitive picture.
That variance is not a contradiction. ChatGPT is strongest where users intentionally open an assistant for writing, coding, brainstorming, research, and multi-step reasoning. Google is strongest where users begin in a search box. Gemini benefits from Android, Google Workspace, Search, and consumer integration. Claude has a professional and coding audience. Perplexity attracts users who want citation-led answers. Copilot benefits from Microsoft’s enterprise footprint. Grok benefits from X and real-time social context.
| Platform Or Surface | Best Current Metric | 2026 Reach Or Share Signal | SEO Impact |
| Google Search plus AI Overviews | Search share and AI Overview reach | 91.27% global search share in June 2026 and over 2.5 billion AI Overview monthly users | Largest discovery surface; optimise for Search, citations, and answer eligibility |
| ChatGPT | Standalone AI chatbot share | 76.87% in StatCounter’s June 2026 AI chatbot tracker | Strongest direct assistant channel; monitor source mentions and referral leakage |
| Gemini | Assistant share plus Google ecosystem reach | 7.94% in StatCounter’s June 2026 AI chatbot tracker | Important because Gemini connects to Search, Workspace, Android, and Google AI plans |
| Perplexity | Citation-led AI search usage | 7.91% in StatCounter’s June 2026 AI chatbot tracker | High-value for research-intent audiences; citations are visible and auditable |
| Claude | Professional reasoning and coding usage | 3.74% in StatCounter’s June 2026 AI chatbot tracker | Useful for B2B, developer, and document-heavy discovery paths |
| Copilot | Enterprise workflow usage | 3.49% in StatCounter’s June 2026 AI chatbot tracker | May influence buying inside Microsoft 365 even when web referrals are modest |
In our hands-on testing, this produced a practical split. ChatGPT was better for broad conversational research and multi-turn synthesis. Perplexity made source inspection faster. Gemini mattered when a query overlapped with Search or Google productivity contexts. Claude was stronger when document reasoning and careful writing outweighed live-search discovery. Copilot was less visible as an open-web research destination but more plausible as a work-graph answer layer inside companies already standardised on Microsoft 365.
The SEO takeaway is not to chase every platform equally. A media brand, a software vendor, and a professional services firm will see different AI journeys. Comparing the chatbot comparison 2026 landscape against your own customer-intent map is more useful than building a generic league table that pretends all prompts have equal commercial value.
The Challenger Layer: Gemini, Perplexity, Claude, Grok, and Copilot
The challenger layer is meaningful precisely because it is not trying to win on the same axis. Gemini is the most obvious challenger to ChatGPT in consumer AI because Google can route usage through Search, Android, Workspace, and paid AI plans. Perplexity is more narrowly positioned around answer search and citations. Claude competes on reasoning quality, code, long-form work, and enterprise controls. Grok leans into real-time web and X context. Copilot turns AI search into a productivity and enterprise knowledge layer.
Aravind Srinivas has framed Perplexity’s path as a longer company-building story rather than a short-term exit, telling Business Insider that IPO planning still pointed around 2028. That matters because Perplexity’s share is not just a percentage point in a tracker. It represents a user behaviour: people who want answers with visible sources, not just a conversational response. For publishers, that makes Perplexity smaller than Google but easier to audit because citations and source cards are central to the interface.
Claude’s role is different. Anthropic’s public pricing page emphasises research, memory, projects, connectors, Microsoft 365, enterprise search, web search, code execution, and model/API pricing. That feature mix is less about replacing Google and more about becoming the reasoning interface for professional work. In B2B markets, that can matter more than raw consumer reach because a single analyst, developer, buyer, or consultant may use an assistant to shortlist vendors before anyone opens a browser.
Grok and Copilot also complicate market-share maths. xAI’s public pricing page highlights real-time web and X search, apps, connectors, business controls, and enterprise security features, but the fetched official page did not expose all dollar prices in machine-readable text during verification. Microsoft Copilot, meanwhile, is priced and packaged through Microsoft 365 business plans, which means usage may be deeply embedded in work software rather than visible as a distinct AI search referral. This is why the best AI search engine for a publisher may not be the same as the best assistant for an enterprise analyst.
Pricing and Limits Shape the Market More Than Branding
Pricing is now a market-share signal because AI search is compute-intensive. A tool can attract free users, but sustained research, file analysis, image generation, coding, deep research, agents, connectors, enterprise search, and API calls all push users into paid tiers. In that sense, the 2026 market is rationed by limits as much as it is won by branding.
OpenAI’s ChatGPT pricing page confirms Free, Go, Plus, and Pro tiers with increasing access to GPT-5.5 Instant, GPT-5.5 Thinking, GPT-5.5 Pro, file uploads, image creation, deep research, agent mode, Codex, projects, tasks, memory, and context. The page repeatedly states that limits apply, and the Pro tier is still governed by abuse guardrails. Google’s AI plans similarly bundle storage, Gemini access, Deep Research, AI Mode in Search, NotebookLM, AI Studio, Antigravity, cloud credits, and higher usage limits across Plus, Pro, and Ultra.
| Platform | Current Public Pricing Or Plan Signal | Search-Relevant Features | Known Constraint Or Limit |
| ChatGPT | Free, Go, Plus, and Pro are listed on OpenAI’s public pricing page; current search-result snippets showed Plus at 20 USD monthly and Pro from 100 USD monthly | Search, GPT-5.5 models, deep research, agent mode, Codex, projects, memory, file uploads | Exact public message caps vary by plan and are described as limits, not fixed quotas |
| Google Gemini and AI Plans | Google AI Plus, Pro, and Ultra plans bundle storage with Gemini and Search AI access | AI Mode in Search, Deep Research, Gemini app, NotebookLM, AI Studio, Antigravity, cloud credits | Usage multipliers are public, but exact daily prompt ceilings are not always disclosed |
| Perplexity | Public enterprise pricing showed Pro at 17 USD monthly billed annually, Enterprise Pro at 34 USD, and Enterprise Max at 271 USD per seat monthly billed annually | Pro Search, model choice, premium citations, work-app search, Spaces, uploads, APIs, enterprise controls | Consumer Pro and Max usage ceilings are described as higher limits rather than stable public caps |
| Claude | Anthropic publishes Team and Enterprise plans plus API model pricing per million tokens | Research, memory, skills, connectors, Microsoft 365, enterprise search, web search, code execution | Individual plan dollar amounts were not fully visible in the retrieved official pricing HTML |
| Microsoft Copilot | Business pricing depends on Microsoft 365 plan bundles and licensing | Web-grounded Copilot Chat, Microsoft 365 data grounding, connectors, files, Work IQ | Some plans carry a 300-user business-plan ceiling before enterprise licensing |
| Grok | xAI’s pricing page lists Free, SuperGrok Lite, SuperGrok, SuperGrok Heavy, Business, and Enterprise | Real-time web and X search, apps, image and video generation, connectors, admin controls | Official page verification confirmed plan families and features, but not all dollar prices |
Perplexity is notable because its enterprise page exposes seat pricing and a clear escalation path from Pro to Enterprise Pro to Enterprise Max. Microsoft is notable for the opposite reason: Copilot economics often sit inside broader Microsoft 365 licensing. Anthropic is transparent about API model pricing, including model-specific input and output rates, plus search and code-execution charges, but individual consumer and team plan pricing can be less visible depending on page rendering and region.
The hidden pricing trap is not simply monthly cost. It is the limit at the exact moment a team scales a workflow. Deep research, agentic browsing, large file uploads, connectors, enterprise search, and API calls can all hit ceilings faster than a casual user expects. That is why pricing comparisons should record plan name, usage limit language, model access, file caps where published, connector access, admin controls, data-retention terms, and whether the feature works on consumer, team, or enterprise plans.
Features, Specs, APIs, and Integrations That Matter
A serious 2026 comparison has to look beyond brand share and list the features that actually affect discovery. For Google, the search-relevant stack includes Search, AI Overviews, AI Mode, Gemini, Deep Research, NotebookLM, AI Studio, Antigravity, workspace integrations, and the broader Ads ecosystem. For OpenAI, the relevant stack includes ChatGPT Search, GPT-5.5 Instant, GPT-5.5 Thinking, GPT-5.5 Pro, deep research, agent mode, Codex, file uploads, projects, tasks, custom GPTs, memory, connectors where enabled, and API access for developers.
For Perplexity, the search-relevant stack includes core answer search, Pro Search, Spaces, file uploads, image generation, model selection across major providers, premium citations, team file and work-app search, SSO, SCIM, data controls, and API endpoints such as web search, URL fetching, people search, and finance search. The API pricing published by Perplexity is especially useful because it separates invocation-based search tools from underlying model-provider rates.
For Claude, the relevant public feature set includes projects, artifacts, research, memory, skills, connectors, web search, enterprise search, Microsoft 365 integration, code execution, Claude Code, and API pricing by model family. For Copilot, the practical features are web-grounded chat, Microsoft 365 grounding, referenced files, uploaded files, connectors, Work IQ, Teams and Office app integration, and security controls inherited from Microsoft enterprise environments. For Grok, xAI lists real-time web and X search, image and video generation, apps, connectors, business analytics, role-based access, SSO, SCIM, audit controls, encryption keys, dedicated data planes, and a no-training enterprise posture.
The API layer is where market share becomes operational. A content team can use public pages to publish, but a product team can also build answer-search features, citation workflows, support bots, sales assistants, or knowledge-base retrieval against vendor APIs. The bottlenecks are predictable: cost per query, model latency, source freshness, quote fidelity, hallucination risk, rate limits, token windows, connector permissions, and privacy rules. Any vendor comparison that ignores these technical constraints is too shallow for enterprise search strategy.
Technical Workflow: How to Measure AI Search Visibility
When we integrated this measurement workflow in a 2026 test environment, the biggest lesson was that AI search visibility cannot be measured with one dashboard. The workflow had to combine classic rank tracking, server logs, analytics referrals, prompt sampling, source-citation capture, and manual factual review. That may sound heavy, but it prevents a common failure: declaring success because a site ranks well in Google while it is absent from AI answers that buyers use for comparison research.
The technical implementation should begin with a prompt taxonomy. Group queries into informational, comparison, commercial, navigational, local, and post-purchase support intents. For each prompt, record the platform, date, account state, location setting where applicable, model or mode, exact prompt wording, answer text, cited sources, mentioned brands, sentiment, and whether the answer includes an error. Repeat the same prompt several times because generative systems vary.
| Step | System Or Data Source | Known Constraint | Output |
| Build prompt sets | Keyword research, sales calls, support tickets, SERP data | Prompts must match real user language, not just SEO keywords | Intent-segmented prompt library |
| Run AI answer tests | ChatGPT, Gemini, Perplexity, Claude, Copilot, Grok, Google AI Mode | Answers vary by account, region, mode, and freshness | Citation, mention, sentiment, and accuracy records |
| Compare with Search | Google Search Console, rank tracking, analytics, log files | AI Overviews may influence users without sending a separate referral | Gap map between rankings and AI answer inclusion |
| Audit source quality | Cited pages, schema, author pages, references, update dates | Models may cite outdated or secondary pages | Fix list for evidence, freshness, and topical authority |
| Monitor limits and cost | Vendor pricing pages, API logs, billing exports | Deep research and agentic workflows can hit caps quickly | Cost-per-answer and usage-risk dashboard |
Performance bottlenecks usually appear in three places. First, prompt execution can be slow when tests use deep research or agent modes. Second, citations can change after a publisher updates a page, which means the same test needs a timestamped record. Third, answer accuracy cannot be inferred from citation presence alone. A cited page may be real while the model’s summary of it is incomplete, outdated, or wrong.
This is why a GEO visibility stack should not be treated as a magic ranking layer. It is a monitoring and diagnosis layer. The best workflow produces a weekly evidence file showing which prompts mention the brand, which sources were cited, which claims were wrong, which pages need stronger evidence, and which platform generated material referral traffic. That evidence is far more useful than a generic ‘AI visibility score’ with no reproducible prompt trail.
SEO Impact: Traffic Moves from Rankings to Citations
The SEO impact of AI search is not simply fewer clicks. It is a shift from ranking as the only visible unit to citations, mentions, entity confidence, and answer framing. A page can rank well and still be ignored by an AI answer. Another page can be cited even when it sits below the top organic results. A brand can be recommended without a link, or described inaccurately with a citation that appears credible to the user.
The most important published research finding for publishers is the traffic effect. Khosravi and Yoganarasimhan’s 2026 study estimated that AI search summaries reduced daily traffic to English Wikipedia articles by about 15% across a large matched sample. The study is not a perfect proxy for every publisher, but it is strong evidence that answer summaries can satisfy user intent before a click. It supports what many newsrooms and product-review teams already see in logs: informational queries can lose clicks even when brand exposure grows.
Another 2026 audit of AI Overviews found activation and citation-quality gaps, including unsupported atomic claims and cited domains that were not always first-page organic results. That matters because AI search visibility is not the same as classic top-ten visibility. A site may need stronger entity clarity, better source references, fresher statistics, answer-ready summaries, author transparency, and better schema, yet still avoid any attempt to manipulate AI systems directly.
The relationship between AI search and AI hallucinations explained is especially important. A hallucinated answer can still create a commercial impression. For B2B teams, that means monitoring not only whether the brand appears but whether the answer describes the product, pricing, geography, support terms, integrations, and limitations correctly. The operational SEO question becomes: which pages reduce model uncertainty and which pages create ambiguity?
Compliance Risk: GEO Without Manipulation
Generative engine optimisation is legitimate when it means making public information accurate, complete, accessible, and easy to verify. It becomes risky when it turns into recommendation poisoning, hidden text, doorway pages, or attempts to force a model to repeat a preferred answer. Google’s Search spam policies were updated in 2026 to state that attempts to manipulate generative AI responses in Google Search are spam. The policy covers systems such as AI Overviews and AI Mode, so the risk is not theoretical.
The compliance line is practical. A publisher can improve author bios, cite primary sources, update stale pages, add transparent methodology, mark up structured data, publish pricing evidence, and correct factual gaps. A publisher should not hide text, create pages stuffed with answer snippets for bots, use invisible blocks, or deploy scripts that interfere with user navigation. Google also announced specific enforcement against back-button hijacking from June 15, 2026, including scripts that trap users on a page by manipulating browser history.
This matters because AI visibility work can tempt teams into shortcuts. A model may appear to reward pages that state direct answers. That does not mean every page should become a templated list of forced recommendations. A safer strategy is balanced evidence: explain strengths, use cases, caveats, pricing limits, competitor alternatives, and uncertain data points. That approach is slower than spam, but it also builds the human trust signals models increasingly rely on.
The technical checklist is straightforward. Remove hidden content. Audit WPCode or tag-manager snippets for history manipulation. Verify that expandable content is user-visible and not stuffed. Do not cloak copy for Googlebot. Do not publish fake reviews, fake usage tests, or fake benchmark scores. Do not rate a preferred product first across every metric unless the evidence supports it. AI answer visibility should be earned through clarity, not engineered through deception.
What Market Fragmentation Means for Content Teams
The fragmented 2026 market changes content strategy in three ways. First, Google remains the default reach engine, so technical SEO, structured content, crawlability, Core Web Vitals, editorial freshness, and source credibility still matter. Second, standalone assistants now deserve their own visibility checks, especially for informational, comparison, technical, and professional-services queries. Third, AI referrals are too narrow as a sole metric because answer influence often happens before or without a click.
For publishers, this means building content around verifiable evidence rather than only around keywords. Primary data, named experts, transparent methodology, date-stamped updates, comparison tables, clear limitations, and accurate pricing notes give both readers and models a better basis for trust. For software companies, it means publishing docs that models can interpret: integration lists, API references, security pages, pricing pages, change logs, and migration guides. For agencies, it means reporting AI visibility separately from ranking reports instead of blending them into a vanity score.
A balanced competitive view is also necessary. Perplexity may be better for citation-led research, but it is not automatically the best answer for every user. ChatGPT may be strongest for multi-turn assistant usage, but its source behaviour and plan limits still matter. Gemini may have unmatched reach through Google, but that also makes its behaviour harder to isolate from Search. Claude may be preferred for reasoning and documents, while Copilot may be decisive inside Microsoft 365. Grok may matter where real-time X context influences discovery.
The final decision model is simple: pick surfaces by audience behaviour. A consumer publisher should prioritise Google AI Overviews and ChatGPT. A B2B SaaS team should add Claude, Perplexity, and Copilot. A finance, recruiting, or public-affairs team may need Grok because real-time social context changes the answer. A research publisher should test Perplexity alternatives and limitations through an alternative to Perplexity AI lens rather than assuming one assistant captures every use case.
Our Editorial Verification Process
This article uses an editorial verification process designed for a fragmented market rather than a single league table. I separated traditional search share, standalone AI-chat share, AI referral traffic, citation visibility, pricing access, and policy risk before drawing conclusions. The core statistical baseline came from StatCounter’s June 2026 global search and AI chatbot trackers, Google’s 2026 AI reach statements, Wix AI Search Lab’s Q1 2026 traffic analysis, market-size trackers, and recent academic studies of AI Overviews and AI search summaries.
The pricing review checked current public pages from OpenAI, Google, Perplexity, Anthropic, Microsoft, and xAI. Where official pages confirmed plan names, features, API charges, usage multipliers, enterprise controls, or seat prices, I treated those as confirmed. Where a vendor described usage as limits without publishing exact quotas, or where the official page did not expose a dollar figure in the retrieved HTML, I stated the limitation instead of inventing a cap. That is why some table cells say limits not publicly confirmed.
For policy verification, I checked Google’s current spam-policy language, including the 2026 addition covering manipulation of generative AI responses, hidden text guidance, and the separate back-button hijacking enforcement notice. I then applied those rules to GEO tactics by distinguishing transparent source improvement from hidden, manipulative, or user-hostile techniques.
Conclusion
The 2026 AI search market is not waiting for one definitive share number because the category itself has split into several measurable behaviours. Google still dominates the broad search surface and has embedded AI into a product billions already use. ChatGPT remains the leading standalone AI assistant by several direct-usage measures. Gemini, Perplexity, Claude, Copilot, and Grok each matter in narrower but commercially important contexts.
The open question is how quickly answer influence will become auditable. Referral traffic is visible, but it undercounts AI answers that satisfy intent without a click. Citation visibility is useful, but it varies by prompt, account, model, region, and time. Pricing is visible in broad tiers, but exact limits can remain opaque until teams hit them in production.
The safest strategic conclusion is balanced rather than dramatic. Traditional SEO remains the foundation because Google Search is still the largest discovery surface. AI visibility is now a parallel discipline because users increasingly ask assistants to summarise, compare, and recommend. The winners will be the teams that measure both, publish evidence that can be verified, and avoid the temptation to manipulate AI answers at the expense of reader trust.
FAQs
What Is the AI Search Engine Market Share in 2026?
There is no single agreed figure. Google dominates overall search reach, while ChatGPT leads standalone AI chatbot usage in several trackers. Smaller assistants such as Gemini, Perplexity, Claude, Copilot, and Grok hold meaningful shares depending on whether the metric is visits, usage, citations, or referrals.
Is ChatGPT Bigger Than Google Search in 2026?
No, not by total search reach. Google remains far larger as a search engine, while ChatGPT is larger in standalone AI assistant usage. The two products compete for informational intent, but they are measured through different market-share categories.
Does Google AI Overview Reduce Website Traffic?
Research suggests it can reduce clicks for some informational pages because users may get an answer before visiting a source. The effect varies by query type, brand strength, source inclusion, and whether the AI answer creates curiosity or satisfies the task completely.
Which AI Search Platform Matters Most for SEO?
Google still matters most for broad organic discovery. ChatGPT matters for direct assistant research. Perplexity matters for citation-led answers. Claude and Copilot matter more in professional and enterprise workflows. The right priority depends on audience intent.
How Should Teams Track AI Search Visibility?
Track classic rankings, AI referrals, prompt-level brand mentions, cited sources, answer accuracy, sentiment, and competitor presence. Repeat prompts over time because generative systems vary by model, account state, geography, and freshness.
Are AI Search Referrals a Reliable Market-Share Metric?
They are useful but incomplete. AI referrals only count clicks from assistants. They miss zero-click answers, brand mentions without links, Google AI Overview exposure, and enterprise workflow answers that never appear in public analytics.
Can Brands Optimise for AI Answers Safely?
Yes, when optimisation means clear evidence, updated facts, transparent authorship, structured data, and accessible documentation. It becomes risky when brands hide text, stuff pages with answer prompts, fabricate reviews, or manipulate browser navigation.
Will Perplexity Replace Google Search?
Not broadly in 2026. Perplexity is influential for source-led research and answer search, but Google remains the largest general search surface. Perplexity is better viewed as a specialised discovery layer rather than a full Google replacement.
References
StatCounter. (2026). AI chatbot market share worldwide. StatCounter AI chatbot market share
StatCounter. (2026). Search engine market share worldwide. StatCounter search engine market share
Alphabet. (2026). Google I/O 2026 keynote: Sundar Pichai. Google I/O 2026 keynote
Google Search Central. (2026). Spam policies for Google web search. Google Search spam policies
OpenAI. (2026). ChatGPT pricing. ChatGPT pricing
Google. (2026). Google AI plans. Google AI plans
Perplexity AI. (2026). Enterprise pricing. Perplexity Enterprise pricing
Anthropic. (2026). Claude pricing. Claude pricing
Khosravi, M., & Yoganarasimhan, H. (2026). The impact of AI search summaries on website traffic. AI search summaries research paper
