
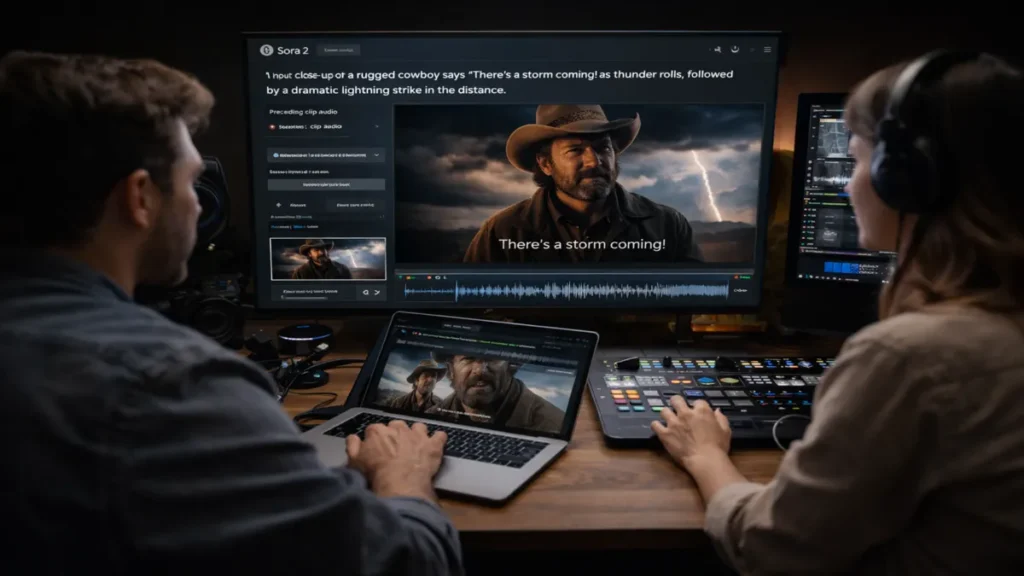
I first encountered Sora 2 not as a technical specification, but as a moment of quiet astonishment — a paragraph of text becoming a moving, speaking, cinematic scene in seconds. What struck me was not just the realism, but the shift in power it represented. Suddenly, describing a scene was enough to direct it. Cameras, actors, lighting, sound, and editing collapsed into language. As I explored how Sora 2 works, from its synchronized audio and lip-synced dialogue to its camera control and physics modeling, I realized this was not merely a new creative tool but a new creative medium. It changes who gets to tell stories, how fast ideas become images, and how easily fiction can resemble fact. This article follows that transformation — tracing how Sora 2 reshapes creativity, culture, and trust in the age of generative video, and why its implications reach far beyond filmmaking into how we understand reality itself.
In the first moments of its release, Sora 2 spread across creative communities not because it was perfect, but because it felt inevitable. People had long imagined that one day you could describe a scene and watch it appear. Sora 2 made that fantasy operational. A rainy alley with whispered dialogue, a basketball game at dusk with crowd noise, a quiet interior moment scored with piano — all could be summoned with words.
This change matters because video is the dominant language of the internet. It shapes advertising, entertainment, politics, and memory. When the ability to create video becomes conversational, the power to shape perception becomes more widely distributed. That redistribution opens creative doors, but it also unsettles long-standing assumptions about evidence, authenticity, and authorship.
Sora 2 is therefore not only a technical product. It is a cultural event. It invites us to rethink what it means to make images, to tell stories, and to trust what we see.
From Sora to Sora 2
The original Sora demonstrated that a language model could generate short, silent clips with surprising coherence. It was a proof of concept rather than a creative platform. Sora 2 expanded that foundation by adding sound, longer duration, and cinematic structure.
The most important leap was audio. Sora 2 can generate dialogue that matches lip movement, ambient sound that reflects the environment, and music that sets emotional tone. These elements turn a moving image into a narrative scene.
Temporal coherence also improved. Characters persist across shots. Lighting remains consistent. Physics behaves plausibly. These qualities make scenes feel continuous rather than fragmented.
Finally, Sora 2 introduced camera control. Users can specify wide shots, close-ups, dolly movements, and point-of-view angles. The model responds not just to what is in the scene, but to how the scene is seen.
Together, these changes transformed Sora from a visual toy into a storytelling instrument.
Read: The Growing Impact of Artificial Intelligence on Society and Everyday Life
Core Capabilities
Sora 2’s defining feature is multimodal continuity. It reasons across time, space, sound, and motion simultaneously.
Lip-synced speech aligns mouth movement with dialogue. Physics modeling governs gravity, collision, and movement. Camera instructions shape visual rhythm. Cameo mode allows insertion of real people or objects with consent verification, addressing ethical concerns around identity misuse.
These capabilities are not isolated features. They are interdependent. A scene feels believable because sound matches space, motion matches physics, and perspective matches narrative intent.
Feature Overview
| Capability | Description | Effect |
|---|---|---|
| Synchronized Audio | Dialogue, effects, music | Emotional depth |
| Lip Sync | Speech-mouth alignment | Realism |
| Camera Control | Pan, dolly, cut, zoom | Cinematic language |
| Physics Simulation | Coherent motion | Credibility |
| Cameo Mode | Consent-based insertion | Ethical personalization |
Why Interest Surged
Sora 2 became visible because it satisfied three conditions at once. It produced results that were visually striking. It reduced production complexity by collapsing many tools into one. And it was accessible enough for non-experts to experiment.
Viral examples showed surreal scenes that were not merely impressive, but expressive. Creators could sketch ideas in video form as easily as writing a paragraph.
Integration into broader AI workflows also played a role. Users research ideas, refine scripts, and generate scenes within a single digital ecosystem, accelerating the path from imagination to artifact.
Prompting as Direction
Prompting Sora 2 is closer to directing than to coding. A prompt is a set of instructions: setting, action, sound, camera. Quoted dialogue triggers lip sync. Describing ambient noise adds texture. Specifying spatial cues shapes depth.
Creators often iterate. They generate a silent clip, refine motion, then layer sound. This mirrors filmmaking practice, compressed into a conversational loop.
The model becomes a collaborator that interprets intent rather than a machine that executes commands.
Prompt Structure
| Element | Example | Role |
|---|---|---|
| Setting | “Rainy alley at night” | Context |
| Action | “Man whispers urgently” | Narrative |
| Audio | “Rain patters, thunder rumbles” | Atmosphere |
| Camera | “Slow dolly forward” | Visual pacing |
API and Professional Use
Beyond casual creation, Sora 2 functions as infrastructure. Approved developers can integrate it through APIs for marketing, education, simulation, and entertainment platforms.
This allows Sora 2 to become part of pipelines for advertising generation, training simulations, interactive storytelling, and virtual environments. It moves from novelty to utility.
Cultural and Ethical Implications
By lowering the cost of video creation, Sora 2 democratizes expression. Small creators gain tools once reserved for studios. Educators can visualize abstract ideas. Activists can tell stories without budgets.
At the same time, the evidentiary value of video declines. If anything can be generated, everything becomes suspect. Trust shifts from medium to context, from image to provenance.
Consent mechanisms and watermarking attempt to mitigate misuse, but social norms will ultimately determine how generative video is interpreted.
Expert Reflections
“We are witnessing the birth of a new visual grammar native to AI.”
“The challenge is not fake video, but universal doubt.”
“Direction is replacing production as the creative bottleneck.”
Timeline
| Year | Event |
|---|---|
| 2024 | Original Sora demonstration |
| 2025 | Sora 2 release |
| 2026 | Expansion into professional platforms |
Takeaways
- Sora 2 merges language and cinema
- It shifts creators from editors to directors
- It democratizes visual storytelling
- It complicates trust in images
- It embeds consent into creative tools
- It signals a new era of synthetic media
Conclusion
Sora 2 is not just a tool for making videos. It is a tool for thinking in motion. It allows ideas to be tested, felt, and seen before they are ever filmed. That changes how stories are born and how culture circulates.
The technology will evolve. The norms will lag behind. What remains is the realization that language now has a visual form, and that the boundary between description and depiction has thinned.
Sora 2 stands at that boundary, turning words into worlds.
FAQs
What is Sora 2?
It is OpenAI’s second-generation text-to-video model with sound and continuity.
How long are clips?
Typically 15 to 25 seconds.
Can it generate audio?
Yes, including dialogue and ambient sound.
Is it available via API?
Yes, for approved and enterprise users.
What is Cameo mode?
A consent-based feature for inserting real identities.
