

I have followed artificial intelligence long enough to recognize when a release marks more than just a technical upgrade. ByteDance’s unveiling of Seedance 2.0 in February 2026 belongs to that rarer category. In a crowded field of generative video tools, this China based system does not simply promise prettier clips. It attempts to solve the deeper problem that has haunted text to video generation since its inception: how to make synthetic footage feel intentional, continuous, and believable.
Within its first demonstrations, Seedance 2.0 showed scenes that obeyed gravity, respected spatial logic, and preserved characters across cuts. Those qualities matter because realism in video is not about resolution alone. It is about coherence. When a character’s face subtly changes between shots or lighting jumps without reason, the illusion breaks. ByteDance appears to understand that video storytelling is as much about consistency as it is about creativity.
In the first hundred words of any conversation about Seedance 2.0, one fact dominates. This model is built for highly realistic text to video generation using a unified multimodal architecture. Text, images, audio, and reference video all feed into a single system designed to think cinematically rather than frame by frame. That design choice sets the tone for everything that follows.
What emerges is not a toy for short viral loops but an engine aimed at professional use. Film previsualization, e commerce product reels, advertising narratives, and longer story driven sequences all sit squarely within its ambitions. Seedance 2.0 does not ask users to accept randomness as a creative partner. It promises control, structure, and visual fidelity that feels closer to filmmaking than prompt gambling.
What Seedance 2.0 Is and Why It Matters


Seedance 2.0 is the latest AI video generation model from ByteDance, the parent company of TikTok and a long standing force in recommendation systems and creative tooling. Officially launched in February 2026, it represents a second major iteration of ByteDance’s internal video foundation models.
At its core, Seedance 2.0 uses a unified multimodal audio video architecture. That phrase matters. Instead of stitching together separate models for sound, motion, and imagery, the system processes them together. Text prompts describe intent. Images define characters or environments. Audio establishes rhythm or mood. Short video clips provide motion references. The model synthesizes all of it into a single output that behaves as though it were planned.
This approach addresses one of the longest standing weaknesses of generative video. Earlier systems often produced visually striking moments that collapsed under scrutiny. Physics drifted. Characters morphed. Camera logic felt arbitrary. Seedance 2.0 targets these flaws directly by modeling temporal continuity and material interaction more explicitly.
For ByteDance, the strategic value is clear. The company already sits at the intersection of creators, advertisers, and algorithmic distribution. A tool that can generate cinematic quality video on demand compresses production timelines and lowers creative barriers. That combination could reshape how visual media is made and monetized across platforms.
Read: Infector Virus Explained: Detection, Removal, and History
Realism as a Design Philosophy



What distinguishes Seedance 2.0 is not one feature but a philosophy. The model treats realism as an engineering target rather than a side effect. Its outputs show careful attention to motion physics, including gravity, inertia, and material response. Fabrics drape instead of float. Water splashes with weight. Shadows behave consistently across moving light sources.
Lighting and color grading also receive unusual emphasis. Seedance 2.0 applies cinematic lighting logic, balancing highlights and shadows in ways familiar to professional cinematographers. Color palettes remain stable across shots, enabling sequences that feel deliberately graded rather than algorithmically averaged.
Perhaps most striking is character persistence. The model can maintain faces, clothing, and proportions across multiple shots. That capability unlocks narrative continuity. A viewer can follow a character through a space without the subtle identity shifts that betray many AI videos. In practice, this means Seedance 2.0 can generate sequences that resemble scenes rather than isolated clips.
Several early reviewers have noted that this realism shifts how users write prompts. Instead of over specifying every frame, creators describe intent and trust the system to respect physical and cinematic rules. That trust marks a turning point in human AI collaboration for video.
Multimodal Control and Instruction Fidelity
Seedance 2.0 accepts an unusually rich set of inputs. Users can combine up to nine images, three video clips, three audio clips, and detailed text instructions in a single generation. Each element serves a role. Images define composition and character identity. Video clips suggest motion style or camera movement. Audio informs pacing and mood.
The system’s instruction following has improved significantly compared to earlier models. Rather than producing loosely related visuals, Seedance 2.0 adheres closely to described shot sequences, camera angles, and transitions. This reduces the trial and error cycle that has frustrated many creators working with generative video.
A product designer can specify a macro close up, followed by a medium lifestyle shot, then a wide environmental reveal. A filmmaker can request a tracking shot that cuts to a close up without losing continuity. These are not trivial gains. They reflect a model trained to respect narrative structure as much as visual flair.
Multi Lens Storytelling and Narrative Continuity

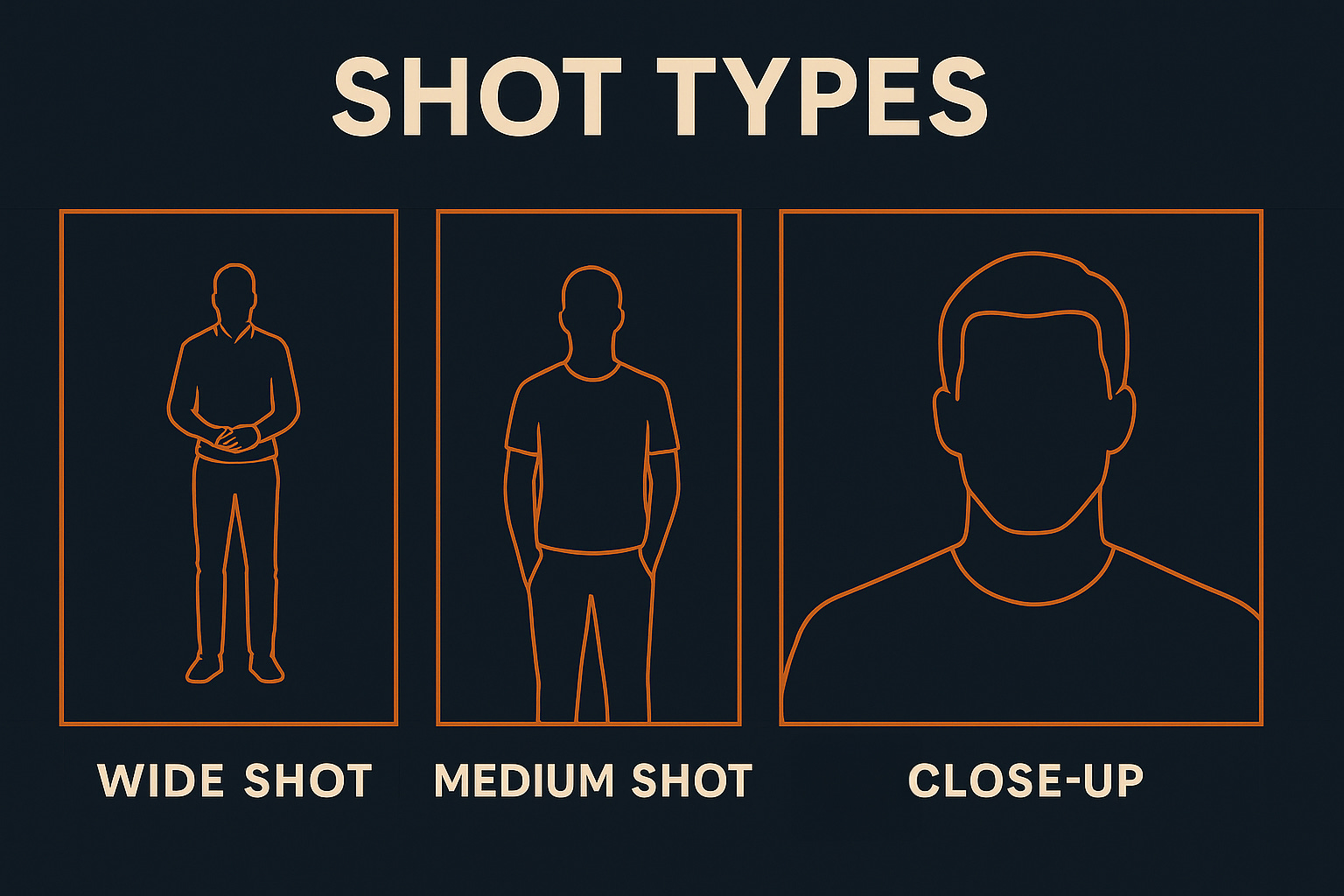

One of Seedance 2.0’s most compelling capabilities is multi lens storytelling. The model can generate several connected shots from a single prompt, each mimicking a different camera lens or angle. Wide establishing shots transition into medium action shots and then into close ups, all while preserving environment, lighting, and character identity.
This matters because traditional filmmaking relies on coverage. Directors capture scenes from multiple angles to control pacing and emotion in the edit. Earlier AI systems struggled with this grammar. Seedance 2.0 internalizes it.
By maintaining consistent internal representations of characters and spaces, the model enables longer narrative segments. Ten to fifteen second sequences feel cohesive rather than stitched together. For advertising and short form storytelling, this coherence can dramatically raise perceived quality.
How Seedance 2.0 Compares With Rivals
The release of Seedance 2.0 inevitably invites comparison with Western counterparts such as Sora and Veo. While standardized public benchmarks remain limited, several patterns emerge from early evaluations.
Seedance 2.0 appears especially strong in structure control and physics realism. Its ability to maintain characters across shots exceeds many first generation systems. Sora has demonstrated impressive imagination and scale, while Veo emphasizes cinematic composition and camera language. Seedance’s distinguishing trait is controllability paired with consistency.
The table below summarizes key differences as described by independent reviewers and vendor documentation.
| Model | Strengths | Noted Limitations |
|---|---|---|
| Seedance 2.0 | Multi shot coherence, physics realism, multimodal control | Limited global availability |
| Sora | Creative diversity, long range imagination | Less deterministic structure |
| Veo | Cinematic framing, camera motion | Early access constraints |
These comparisons remain fluid. The field is evolving rapidly, and each system reflects the priorities of its creators. What matters is that Seedance 2.0 has entered the top tier of generative video models rather than trailing it.
Access, Free Tiers, and Platform Strategy
ByteDance has taken a layered approach to access. In China focused environments, Seedance 2.0 is integrated into platforms such as Jimeng, Xiaoyunque, and Doubao. These offer limited free quotas, trial pricing, or daily allowances designed to encourage experimentation.
Outside China, third party web platforms have begun exposing Seedance 2.0 through browser based interfaces. These typically offer signup credits, capped resolutions, and short clip lengths without requiring payment information. Pro tiers unlock higher resolutions, longer sequences, and commercial rights.
This strategy mirrors ByteDance’s broader ecosystem logic. Seedance 2.0 is not positioned as a standalone product alone. It is an enabling layer across creative apps, marketing tools, and future developer APIs. Free tiers serve as funnels, familiarizing users with the system’s strengths before scaling usage.
Industry Implications and Expert Perspectives
Several researchers and industry analysts see Seedance 2.0 as part of a broader shift toward production ready generative media.
Dr. Kai Fu Lee, a longtime observer of Chinese AI development, has noted that Chinese firms increasingly emphasize applied realism over speculative demos. That focus aligns with Seedance 2.0’s design choices.
Emily Bell, director of the Tow Center for Digital Journalism, has argued that controllable generative video will reshape newsroom visuals and advertising alike by lowering costs while raising ethical stakes.
Meanwhile, advertising technologist Mark Ritson has described AI video tools as a compression of creative labor, where ideation, production, and iteration collapse into a single workflow.
These perspectives converge on a single point. Tools like Seedance 2.0 will not replace human judgment, but they will redefine where that judgment is applied.
Structured Capabilities Overview
The following table outlines Seedance 2.0’s core technical capabilities as described by ByteDance and early platform partners.
| Capability | Description | Practical Impact |
|---|---|---|
| Multimodal input | Text, images, audio, video combined | Fewer iterations, higher intent fidelity |
| Physics modeling | Gravity, motion, material behavior | More believable scenes |
| Character persistence | Identity consistency across shots | Narrative continuity |
| Multi lens sequencing | Wide to close up transitions | Film like storytelling |
Takeaways
- Seedance 2.0 prioritizes realism through physics, lighting, and continuity rather than surface polish alone.
- Unified multimodal architecture enables tighter control over narrative intent.
- Multi lens storytelling bridges the gap between clips and scenes.
- ByteDance positions the model as an ecosystem layer, not a single app.
- Free tiers accelerate adoption while preserving premium pathways.
- Global competition in AI video is intensifying, with no single dominant paradigm yet.
Conclusion
I see Seedance 2.0 as less a spectacle and more a signal. It suggests that the era of AI video as novelty is ending, replaced by a phase where reliability and control matter most. By focusing on cinematic grammar, physical plausibility, and multimodal coherence, ByteDance has built a system that invites serious use.
This does not mean the future of video will be frictionless or free of ethical tension. As generative realism improves, questions of authorship, disclosure, and trust will grow louder. Yet tools like Seedance 2.0 also democratize visual storytelling, allowing smaller teams and individuals to work at a level once reserved for studios.
In that sense, Seedance 2.0 feels less like a competitor to cameras and more like a new kind of camera itself. One that listens to language, watches reference, and imagines motion with increasing discipline. The long arc of visual media has always bent toward accessibility. ByteDance’s latest model bends it further, with consequences that will unfold shot by shot.
FAQs
What is Seedance 2.0 designed for?
Seedance 2.0 targets professional quality text to video generation for film, advertising, and e commerce, emphasizing realism and narrative coherence.
How is Seedance 2.0 different from earlier AI video tools?
It uses a unified multimodal architecture and maintains characters, lighting, and physics across multiple shots.
Can Seedance 2.0 generate longer videos?
Yes, it supports multi shot sequences that feel like continuous scenes rather than isolated clips.
Is Seedance 2.0 free to use?
Limited free tiers exist on ByteDance apps and third party platforms, with paid plans unlocking higher quality output.
Does Seedance 2.0 support audio input?
Yes, users can include audio clips to influence rhythm, mood, and synchronization.





